A New Way to Cite Chandra Data
Raffaele D’Abrusco and the DPAOps team
The Chandra Data Archive (CDA) continues to work to make Chandra data more easily citable and discoverable. Since 2021, each archival Chandra observation is associated with a Digital Object Identifier (DOI), through which a link pointing to the data can be created in a document (see the the CDA article in the 2022 Fall CXC newsletter for details on DOIs for archival observations). This year, we extended our DOI reach to cover the whole domain of data produced by the Chandra X-ray Center by creating DOIs for Chandra Source Catalog (CSC) data products and by introducing Chandra Data Collection (CDC) DOIs.
DOIs for Chandra Source Catalog
The Chandra Source Catalog is the crowning achievement of the expansion of the Chandra data archive. A comprehensive collection of positional, photometric, spectroscopic, and time-variability properties of all X-ray sources detected in public Chandra observations is regularly made available to everyone to disseminate and make more accessible the incredibly rich X-ray sky observed by the Chandra X-ray Observatory. Since CSC version 2.0, the detection of sources has been performed from stacked overlapping observations, when possible, to reach fainter flux regimes and take full advantage of the accumulation of archival observations in the same regions of the sky through the mission’s lifetime. As a plus, all the data products associated with each single X-ray source, the new "stacked" observations, and the single observations processed according to the catalog specifications (which nicely complement the archival versions of single Chandra observations) are published and free to be used for a wide variety of scientific goals that the astronomical community will certainly explore.
More details about the marvelous CSC2.1 can be found here. To allow maximal citability of all CSC data products, starting with the upcoming version 2.1 of the catalog, three new classes of CSC-related DOIs will become available:
-
Catalog-wide CSC DOI:
https://doi.org/10.25574/csc<csc_version_number>
(for example: https://doi.org/10.25574/csc2) -
Stack-level DOI:
https://doi.org/10.25574/csc<csc_version_number>.stk.<detect_stack_id>
(for example: https://doi.org/10.25574/csc2.stk.acisfJ2359567p004249_001) -
Observation-level CSC DOI:
https://doi.org/10.25574/csc<csc_version_number>obs.<obsid>
(for example: https://doi.org/10.25574/csc2.obs.11591)
All CSC DOIs share the same prefix (10.25574) as archival observations DOIs. The only additional information needed to cite the catalog or any distinct stack or catalog-style observation is the major version of the catalog (<csc_version_number>)—which will be 2 for CSC2.1—and the "names" of the stacks (<detect_stack_id>) or observations (<obsid>). CSC DOIs will behave exactly like all other DOIs and will encode a link to a landing page containing metadata and granting access to the actual data. For example, in a LaTeX document using the AASTeX package, the command:
\dataset[<detect_stack_id>]{https://doi.org/10.25574/csc<csc_version_number>.stk.<detect_stack_id>}
will create a link in the pdf to the URL of a webpage containing a summary description of the associated data entity and links to the specific data products for the CSC2.1 stack. The appropriate DOI value will be included in the DS_IDENT keywords of the FITS headers of all CSC data products for quick and efficient programmatic access.
As all types of Chandra data entities get their DOIs, the only risk is needing to have to include a long list of identifiers in your manuscript. Enter the:
Chandra Data Collection DOIs
The original focus of the CDA in its pursuit of full DOI compliance was making sure that every distinct, well-defined data entity based on Chandra observations would be easily citable and findable via their specific identifier. At the same time, we have been working on the best approach to combine any number of "elementary" CXC DOIs into a single DOI that users could cite in their manuscript and be spared from dealing with the complexity of the original list of multiple datasets and associated DOIs. For this glorious purpose, we defined a "Chandra Data Collection" (CDC) as an arbitrary set of citable Chandra data entities (any conceivable combination of archival observations and CSC datasets with DOIs) and determined a minimal set of qualifying metadata for this new concept.
In practice, we developed a procedure that interested users can follow to request the creation of a DOI specific to a CDC they might need to cite. Employing a single CDC DOI as a handy 1-stop replacement for a long, heterogeneous list of DOIs used in a single publication is the most common—but not the only—use case for CDC DOIs. The bottom line for everyone interested in Chandra: if you are using Chandra data for your research, you are encouraged to request a CDC DOI! You can go to this webpage to learn more or jump directly to this webform if you feel ready. The CDA team will work on your request, create the CDC DOIs, and contact you with details about your fresh-out-of-the-oven CDC DOIs.
If data citability by persistent identifiers sits surprisingly high on your list of technical interests and you can't get enough of Chandra-related DOIs, here's a visual representation showing the different categories of DOIs that the CDA creates and maintains and how they relate to different types of data in the Chandra archive and the CSC.
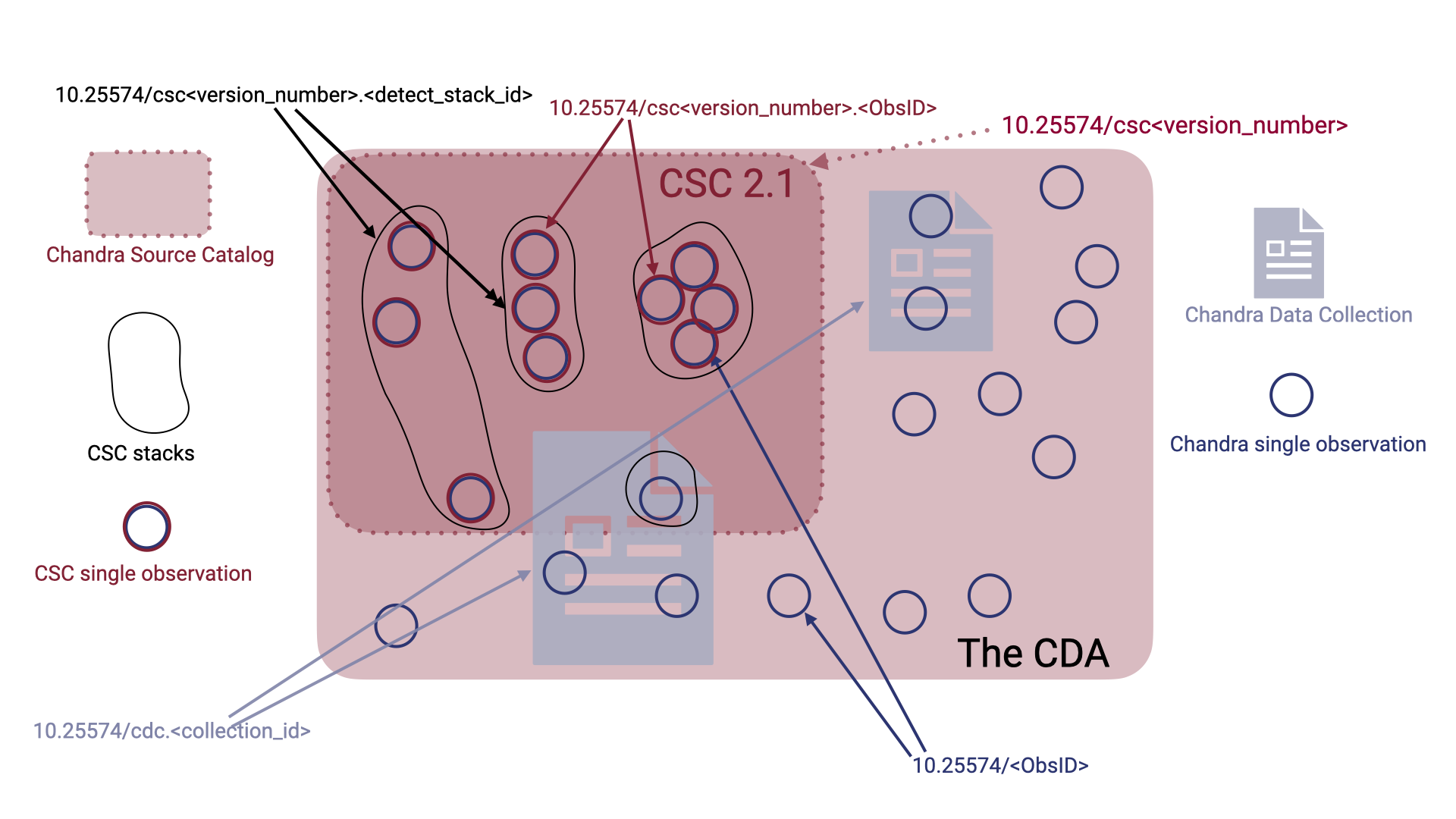
Schematic showing the relations between data types and DOIs. The text at the base of each arrow shows the different names of CDA DOIs, and the arrows point to the data entities the DOIs are associated with. CDC DOIs can overlap both the archive and the CSC because they can contain a generic assortment of Chandra DOIs.
CDC DOIs can be created for any aggregation of Chandra data; their rich metadata trace the semantic relationships between their building blocks to retain full discoverability and ensure that basic provenance information for the data collection is encapsulated in the DOI. CDC DOIs support any imaginable grouping of datasets that share one or more spatial, bibliographic, scientific, or historical traits and are a powerful tool to map, make discoverable, and track the hierarchical growth of the Chandra archive through time. At the CDA we are excited about the potential future applications of this technology and can't wait to share our progress with the Chandra community!
If you want to know more about these subjects and more, shoot us an email at arcops@cfa.harvard.edu.