Next: 2. Sherpa Display Up: Sherpa Reference Manual Previous: List of Tables
This section contains all Sherpa native commands which can be typed at the prompt or included in the input ASCII file. Sherpa also allows the access to the internal information (e.g. about data, statistics, errors etc. ) through many S-lang access functions. For a list of the available functions see Section 8.
Sherpa is the generalized fitting engine of CIAO . Sherpa enables the user to fit models to data, particularly but not exclusively, to data that is being returned by NASA's Chandra X-ray Observatory. Sherpa features syntax that allows the user to construct complex models from simple definitions and to link parameters algebraically.
Below is a list of all Sherpa commands, along with a brief description. Sherpa also understands the S-Lang programming language, as described in AHELP SLANG-CIAO and AHELP SLANG-SHERPA.
| Command | Description |
|---|---|
| $ | Must precede any UNIX command. |
| # | % | Denotes a comment. |
| ANALYSIS | Specifies whether to analyze a given dataset in energy, wavelength, or channel space. |
| BACK | Inputs the contents of one or more background data files. |
| BACKERRORS | BERRORS | Defines an expression to be used for the background errors. |
| BACKGROUND | BG | Defines a model expression to be used for the background. |
| BDCOUNTS | Calculates the sum of observed counts data for background datasets. |
| BEFLUX | Calculates the unconvolved energy flux for background datasets. |
| BGROUP | Applies grouping scheme to background data. |
| BMCOUNTS | Calculates the sum of convolved model amplitudes for background datasets. |
| BSTATERRORS | Defines the statistical errors for background data. |
| BSYSERRORS | Defines systematic errors for background data. |
| BUNGROUP | Undo grouping applied to background data. |
| BYE | EXIT | QUIT | Terminates the Sherpa program. |
| CAST | Casts a dataset to single or double precision. |
| CLOSE | Closes the image display window. |
| COORD | Specifies the coordinate system for use in fits to 2-D images. |
| COVARIANCE | Computes covariance matrices and confidence intervals for thawed parameters. |
| CPLOT | Causes the specified 2-D data to be displayed, with a contour plot. |
| CREATE | Establishes a model component and its parameters. |
| DATA | Inputs the contents of one or more source data files. |
| DATASPACE | Sets a value range on which a source model may be evaluated, when no dataset has been input. |
| DCOUNTS | Calculates the sum of observed counts data for source datasets. |
| ECHO | Turns on/off reporting of user keystrokes. |
| EFLUX | Calculates the unconvolved energy flux for source datasets. |
| EQWIDTH | Computes the equivalent width of an emission or absorption line. |
| ERASE | Erases user inputs and settings, plotting objects, and/or model components. |
| ERRORS | Defines an expression to be used for the source errors. |
| EXIT | BYE | QUIT | Terminates the Sherpa program. |
| EXPMAP | Defines the exposure map model to be used. |
| FAKEIT | Creates a simulated 1-D dataset. |
| FEFFILE | Inputs a Fits Embedded Function (FEF) file. |
| FEFPLOT | Plots an instrument response stored in Fits Embedded Function (FEF) format. |
| FIT | RUN | Initiates fitting. |
| FLUX | Calculates the model or counts flux for 1-D data. |
| FREEZE | Prohibits a model parameter from varying. |
| FTEST | Computes significance using the F test. |
| GETX | Assigns x-axis values taken from a plot to model parameters. |
| GETY | Assigns y-axis values taken from a plot to model parameters. |
| GOODNESS | Reports information about the |
| GROUP | Applies grouping scheme to source data. |
| GUESS | Estimates initial parameter values and ranges, based on input data. |
| IGNORE | Specifies data to be excluded from analyses. |
| IMAGE | Causes the specified 2-D data to be displayed. |
| INSTRUMENT | RESPONSE | Defines the instrument model to be used. |
| INTEGRATE | Controls the integration of model components. |
| INTERVAL-PROJECTION | INT-PROJ | Plots the fit statistic as a function of parameter value, using the PROJECTION algorithm. |
| INTERVAL-UNCERTAINTY | INT-UNC | Plots the fit statistic as a function of parameter value, using the UNCERTAINTY algorithm. |
| JOURNAL | Turns on/off writing of all commands to a file. |
| LPLOT | Causes the specified 1-D data to be displayed. |
| MCOUNTS | Calculates the sum of convolved model amplitudes for source datasets. |
| METHOD | SEARCHMETHOD | Specifies the optimization method. |
| MLR | Computes significance using the Maximum Likelihood Ratio test. |
| NOTICE | Specifies data to be included in analyses. |
| OPEN | Opens the specified data display window. |
| OPLOT | Causes multiple data curves to be displayed in the same drawing area. |
| PARAMPROMPT | Turns on/off prompting for model parameter values. |
| PLOTX | Sets the unit type for the x-axis of the plot. |
| PLOTY | Sets the unit type for the y-axis of the plot. |
| PRECISION | Controls the precision of numerical values displayed with SHOW. |
| PROJECTION | Estimates confidence intervals for thawed parameters. |
| PROMPT | Changes the Sherpa prompt. |
| QUIT | BYE | EXIT | Terminates the Sherpa program. |
| READ | Inputs the contents of one or more files. |
| RECORD | Toggles on/off writing of fit parameter values and statistics. |
| REGION-PROJECTION | REG-PROJ | Creates a contour plot of confidence regions, computed using the PROJECTION algorithm. |
| REGION-UNCERTAINTY | REG-UNC | Creates a contour plot of confidence regions, computed using the UNCERTAINTY algorithm. |
| RENAME | Changes the name that has been given to a model component. |
| RESET | Restores settings and/or parameter values. |
| RESPONSE | INSTRUMENT | Defines the instrument model to be used. |
| RUN | FIT | Initiates fitting. |
| SAVE | Causes settings, definitions, filters, and/or parameter values to be written to an ASCII file. |
| SEARCHMETHOD | METHOD | Specifies the optimization method to be used. |
| SET | Sets options for plots generated with LPLOT. |
| SETBACK | Sets time and backscal attributes for background datasets. |
| SETDATA | Sets time and backscal attributes for datasets. |
| SHOW | Reports current status. |
| SOURCE | SRC | Defines the source model expression to be used for fitting a dataset. |
| SPLOT | Causes the specified 2-D data to be displayed, with a surface plot. |
| STATISTIC | Specifies the fitting statistic. |
| SUBTRACT | Performs background subtraction. |
| STATERRORS | Defines the statistical errors for source data. |
| SYSERRORS | Defines systematic errors for source data. |
| THAW | Allows a model parameter to vary. |
| TRUNCATE | Resets negative model amplitudes to zero. |
| UNCERTAINTY | Estimates confidence intervals for thawed parameters. |
| UNGROUP | Undo grouping applied to source data. |
| UNLINK | Removes a link between model parameters. |
| UNSUBTRACT | Performs an undo of background subtraction. |
| USE | Calls and executes a Sherpa script. |
| VERSION | Reports the Sherpa version that is in use. |
| WCS | Sets the WCS for use as the 2D coordinate system. |
| WEIGHT | Assigns a weight value to data. |
| WRITE | Causes the specified information to be written to a file. |
| XSPEC ABUNDAN | Performs the XSPEC command abund, which sets abundancies. |
| XSPEC XSECT | Performs the XSPEC command xsect, which sets the photoelectric cross-section. |
In this Chapter, we describe all Sherpa commands, in alphabetical order by command name. These descriptions are meant to serve as a quick reference for Sherpa users. Beginning Sherpa users may wish to first review Sherpa Threads, available from
http://cxc.harvard.edu/sherpa/before utilizing this reference.
Each command section includes a description of the command purpose and syntax, along with any other relevant information and examples. Note that each section's set of examples should be run from a newly begun Sherpa session. When there are multiple examples within a section, they should be run consecutively.
Information about commands is also available within Sherpa with the command AHELP.
The following conventions are herein used for describing the syntax:
Once CIAO has been installed, Sherpa may be launched by typing sherpa on the command line. Or, Sherpa may be launched using a command-line option:
SHERPA, version 2.2
Copyright (C) 1999-2001, Smithsonian Astrophysical Observatory
Usage: sherpa [options] [FILE]
Options:
--slscript SCRIPT Run the given S-Lang script before launching sherpa.
This script may contain any valid S-Lang construct,
including sherpa_eval() and varmm I/O statements.
-h, -help, --help Display this message
--batch Don't show copyright; exit after loading FILE
FILE is optional, and may contain only sherpa commands or simple (one line)
S-Lang statements.
The user may create customized Sherpa defaults, by creating a file in their home directory named .sherparc that contains Sherpa commands. For example, the following .sherparc file will cause prompting for model parameter values to be turned OFF, and will change the default optimization method from POWELL to LEVENBERG-MARQUARDT:
unix% more ~jsmith/.sherparc PARAMPROMPT OFF METHOD LEVENBERG-MARQUARDT
Must precede any Unix command issued within Sherpa or ChIPS.
sherpa> $<arg> chips> $<arg>
where ![]() arg
arg![]() is a Unix command. Alternatively,
! can be used in place of $.
is a Unix command. Alternatively,
! can be used in place of $.
However, the Unix command cd is an exception to this syntax, and must be issued within Sherpa or ChIPS without a preceding $ character.
The Unix commands ls and pwd are also exceptions to this syntax, and may or may not be issued within Sherpa or ChIPS without a preceding $ character.
Examples:
Issue various Unix commands within Sherpa:
sherpa> cd /disks/a/mydata sherpa> ls sherpa> pwd /disks/a/mydata
Issue various Unix commands within Sherpa:
sherpa> $more data.dat 0.5 1.80766 1.5 2.21929 2.5 2.64117 3.5 3.10638 4.5 3.51711 5.5 3.74749
Use a Unix command to clear the screen:
sherpa> $clear
This Unix command will clear the screen.
Denotes a comment. The symbol % also denotes a comment.
sherpa> {# | %} <arg>
chips> {# | %} <arg>
where <arg> is a comment.
Examples:
Issue a comment:
sherpa> # My comment sherpa> POLY[modela]
chips> # My comment chips> CURVE data/example.dat X 1 Y 2
Specifies whether to analyze datasets in energy, wavelength, or channel space.
sherpa> ANALYSIS [<dataset range> | ALLSETS] \
[{ ENERGY | WAVELENGTH | CHANNELS | BINS }]
where ![]() dataset range
dataset range![]()
![]() #, or more generally
#:#,#:#,..., such that # specifies a dataset number, and #:#
represents an inclusive range of datasets; one may specify multiple
inclusive ranges by separating them with commas. The default for
ANALYSIS is all datasets (ALLSETS).
#, or more generally
#:#,#:#,..., such that # specifies a dataset number, and #:#
represents an inclusive range of datasets; one may specify multiple
inclusive ranges by separating them with commas. The default for
ANALYSIS is all datasets (ALLSETS).
The WAVELENGTH argument may be shortened to WAVE.
The analysis setting for each specified dataset is shown if the final argument is omitted, e.g. "ANALYSIS ALLSETS".
The analysis setting is automatically determined when data are read in. This setting can be altered with the ANALYSIS command. In general, the analysis setting for non-PHA data is CHANNELS (synonymous with BINS), while for general PHA files it is ENERGY. When the columns BIN_LO and BIN_HI are detected in a Type II PHA file (such as can be the case for files containing Chandra grating data), these are assumed to contain wavelength information and the analysis is set to WAVELENGTH.
PHA datasets for which there is an INSTRUMENT model set may be analyzed in either ENERGY or WAVE space. Setting ANALYSIS to WAVE or ENERGY has no effect until an ARF and/or an RMF are read in and an INSTRUMENT is specified.
If the ANALYSIS setting is changed after the model components and their parameter values and ranges have been set, issue the GUESS command to reset the initial values and ranges.
Some models, such as certain XSPEC models, expect that the x-values will always be energy bins. When the analysis setting is using non-energy bins (e.g., WAVE) and an XSPEC model is defined, Sherpa converts the bins to energy before sending them to the XSPEC model. After the XSPEC model finishes, Sherpa converts back to the original units. Sherpa also scales the model values appropriately (e.g., if counts/keV came out of the XSPEC model, and Sherpa is working with wavelength bins, then Sherpa scales the output of the XSPEC model to counts/Angstrom).
Examples:
Read in Chandra grating data and a grating RMF. Analyze
the O VIII Lyman ![]() line at 18.97
Å in energy space,
in the dataset (# 9) containing MEG -1 order counts:
line at 18.97
Å in energy space,
in the dataset (# 9) containing MEG -1 order counts:
sherpa> DATA data_pha2.fits
The inferred file type is PHA Type II. If this is not what you want, please
specify the type explicitly in the data command.
Warning: could not find SYS_ERR column
WARNING: statistical errors specified in the PHA file.
These are currently IGNORED. To use them, type:
READ ERRORS "<filename>[cols CHANNEL,STAT_ERR]" fitsbin
WARNING: backgrounds UP and DOWN are being read from this file,
and are being combined into a single background dataset.
WARNING: multiple datasets have been input.
The next available dataset number is 13.
sherpa> PARAMPROMPT OFF
sherpa> RSP[a]
sherpa> a.rmf = meg1.rmf
sherpa> a.arf = meg1.arf
sherpa> INSTRUMENT 9 = a
sherpa> IGNORE 9 ALL
sherpa> NOTICE 9 WAVE 18.8:19.2
sherpa> SOURCE 9 = CONST[co] + GAUSS[g]
sherpa> FIT 9
LVMQT: V2.0
LVMQT: initial statistic value = 42730.9
LVMQT: final statistic value = 21.8345 at iteration 74
co.c0 0.000378496
g.fwhm 0.00194331
g.pos 18.9812
g.ampl 1.53444
sherpa> SHOW g
gauss1d[g] (integrate: on)
Param Type Value Min Max Units
----- ---- ----- --- --- -----
1 fwhm thawed 1.9433e-03 6.8361e-04 6.8361
2 pos thawed 18.9812 18.7975 19.1975
3 ampl thawed 1.5344 1.3713e-03 13.7131
sherpa> ANALYSIS 9 ENERGY
sherpa> GUESS SOURCE 9
sherpa> FIT 9
LVMQT: V2.0
LVMQT: initial statistic value = 43170.1
LVMQT: final statistic value = 21.7635 at iteration 66
co.c0 0.0112294
g.fwhm 0.000107187
g.pos 0.653184
g.ampl 27.7522
sherpa> SHOW g
gauss1d[g] (integrate: on)
Param Type Value Min Max Units
----- ---- ----- --- --- -----
1 fwhm thawed 1.0719e-04 2.3488e-05 0.2349
2 pos thawed 0.6532 0.6457 0.6594
3 ampl thawed 27.7522 3.9868e-02 398.6771
Inputs the contents of one or more background data files.
sherpa> BACK [# [ID]] <filespec> [,[# [ID]] <filespec>,...]
where # specifies the number of the dataset to be associated with this background data file (default dataset number is 1). The ID modifier is used if and only if the Sherpa state object variable multiback is set to 1, i.e., if more than one background dataset is to be associated with a single source dataset. The ID modifier may be any unreserved string (e.g., A, foo, etc.), i.e., a string that is not a parsable command.
Alternative means of reading in background datasets involve using the load functions of the Sherpa/S-Lang module (e.g., load_bpha).
The help file for the READ command explains the ![]() filespec
filespec![]() definition and has a listing of allowed file types; see also the related
commands BACKGROUND, BACKERRORS, and SETBACK.
definition and has a listing of allowed file types; see also the related
commands BACKGROUND, BACKERRORS, and SETBACK.
A few things to note:
unix% dmcopy "infile.fits[spec 1][spec 2]" outfile.fits
you can also do
sherpa> back "infile.fits[spec 1][spec 2]"
This is especially useful when working with very large files. For example:
sherpa> back "evt.fits[bin sky=4][opt mem=100]"
bins the event file by a factor of four and allocates additional memory. A similar command (omitting the binning factor) can be used to read in an image.
Examples:
Input 2-D FITS image data and background files; subtract and unsubtract background data:
sherpa> DATA 3 example_img.fits FITS sherpa> BACK 3 example_img_bkg.fits FITS sherpa> SUBTRACT 3 sherpa> UNSUBTRACT 3
The first command, DATA 3 example_img.fits FITS, reads the FITS image example_img.fits, as dataset number 3. The second command reads the background FITS image for this dataset. The third command, SUBTRACT 3, performs the background subtraction for dataset number 3. The final command, UNSUBTRACT 3, restores dataset number 3 to its original unsubtracted state.
Input IMH image data and background files, then subtract the background:
sherpa> DATA example.imh sherpa> BACK example_bkg.imh sherpa> SUBTRACT
The first two commands read in the image and background image, respectively, for dataset 1. SUBTRACT subtracts the background from the data.
Defines an expression to be used to specify the statistical errors for background data. The commands BACKERRORS and BSTATERRORS are equivalent.
sherpa> BERRORS [<dataset range> | ALLSETS] [ID] = <errorExpr>
![]() dataset range
dataset range![]()
![]() # (or more generally #:#,#:#,
etc.) such that
#
specifies a dataset number and #:# represents an inclusive range of datasets;
one may specify multiple inclusive ranges by separating them with
commas. The default dataset is dataset 1.
The ID modifier is used if and only if the Sherpa state
object variable multiback
is set to 1, i.e., if more than
one background dataset is to be associated with a single source dataset.
The ID modifier may be any unreserved string
(e.g., A, foo, etc.), i.e.,
a string that is not a parsable command.
# (or more generally #:#,#:#,
etc.) such that
#
specifies a dataset number and #:# represents an inclusive range of datasets;
one may specify multiple inclusive ranges by separating them with
commas. The default dataset is dataset 1.
The ID modifier is used if and only if the Sherpa state
object variable multiback
is set to 1, i.e., if more than
one background dataset is to be associated with a single source dataset.
The ID modifier may be any unreserved string
(e.g., A, foo, etc.), i.e.,
a string that is not a parsable command.
The error expression, ![]() errorExpr
errorExpr![]() , may be composed of one or
more (algebraically-combined) of the following elements:
, may be composed of one or
more (algebraically-combined) of the following elements:
| Component: | Description: |
| BACK | An input background dataset |
| numericals | Numerical values |
| operators |
A few things to note:
See the related command BSYSERRORS.
The background errors are accessible to the Sherpa/S-Lang module user via the functions get_berrors and set_berrors.
Examples:
Define an expression to be used for the background errors. They are set to 1.5 in each bin.
sherpa> DATA data.dat sherpa> BACK back.dat sherpa> BERRORS = 1.5
Define an expression to be used for the background errors. They are set to 0.5 times the background datum in each bin.
sherpa> BERRORS = 0.5*BACK
Defines a model expression to be used for the background. The command BG is an abbreviated equivalent.
sherpa> BACKGROUND [<dataset range> | ALLSETS [ID]] = <modelExpr>
![]() dataset range
dataset range![]()
![]() # (or more generally
#:#,#:#, etc.) such that # specifies a
dataset number and #:# represents an inclusive range of
datasets; one may specify multiple inclusive ranges by separating them
with commas. The default dataset is dataset 1. The ID
modifier is used if and only if the Sherpa state object
variable multiback is set to 1, i.e., if more than one
background dataset is to be associated with a single source dataset.
The ID modifier may be any unreserved string (e.g., A,
foo, etc.), i.e., a string that is not a parsable command.
# (or more generally
#:#,#:#, etc.) such that # specifies a
dataset number and #:# represents an inclusive range of
datasets; one may specify multiple inclusive ranges by separating them
with commas. The default dataset is dataset 1. The ID
modifier is used if and only if the Sherpa state object
variable multiback is set to 1, i.e., if more than one
background dataset is to be associated with a single source dataset.
The ID modifier may be any unreserved string (e.g., A,
foo, etc.), i.e., a string that is not a parsable command.
The model expression,
![]() modelExpr
modelExpr![]() ,
is an algebraic combination of one or more of the following elements:
,
is an algebraic combination of one or more of the following elements:
{<sherpa_modelname> | <sherpa_modelname>[modelname] |
<modelname> | <model_stack> | <nested_model>}
along with numerical values. The following operators are
recognized: ![]() - * / ( ) { }.
See the CREATE command for further information.
- * / ( ) { }.
See the CREATE command for further information.
Note that:
To reset a background model stack, issue the command:
sherpa> BACKGROUND [<dataset range> | ALLSETS] =
How the background model stack is used depends upon whether or not the the source data have been background-subtracted:
Note on Model Normalization. Because the background is, by definition, an "extended object," the normalization of a best-fit background model will be affected by the size of the background extraction region, which is proportional to the area of the sky from which the photons came. In particular, if the areas of the source and background extraction regions differ, then the normalization may not be easily interpretable: which region does it correspond to? In CIAO 3.0, the rules are the following:
Examples:
Define a model to be used for the background and set background model parameter values:
sherpa> DATA 2 data.dat sherpa> BACKGROUND 2 = GAUSS GAUSS.fwhm parameter value [10] GAUSS.pos parameter value [0] 3 GAUSS.ampl parameter value [1] 2:1:10
This command defines the Sherpa model GAUSS as the background model for dataset
number 2. The user accepted the given initial guessed value for
the parameter fwhm (using the ![]() RETURN
RETURN![]() key),
entered a value of 3 for parameter pos, and entered a
value of 2 (with min:max range of 1:10) for parameter ampl.
key),
entered a value of 3 for parameter pos, and entered a
value of 2 (with min:max range of 1:10) for parameter ampl.
Define a model to be used for the background and set the parameter values:
sherpa> PARAMPROMPT OFF Model parameter prompting is off sherpa> DATA data.dat sherpa> POISSON[bkgA] sherpa> BACKGROUND = bkgA
In the third command, the name bkgA is given to the Sherpa model component POISSON. The final command defines this model as the model to be used for the background.
Create a background model expression:
sherpa> PARAMPROMPT ON Model parameter prompting is on sherpa> BACKGROUND = (POW[modelc])/2 modelc.gamma parameter value [0] modelc.ref parameter value [1] modelc.ampl parameter value [1]
This command assigns the model expression
(POW![]() modelc
modelc![]() )/2, to the background model for dataset
number 1. In this example, the user accepted
the given initial values for all of the parameters via parameter
prompting.
)/2, to the background model for dataset
number 1. In this example, the user accepted
the given initial values for all of the parameters via parameter
prompting.
See the SOURCE command documentation for more (analogous) examples.
Calculates the sum of observed counts data for background datasets.
See the DCOUNTS command for information.
Calculates the unconvolved energy flux for background datasets.
See the EFLUX command for information.
Applies grouping scheme to background data.
See the GROUP command for information.
Calculates the sum of convolved model amplitudes for background datasets.
See the MCOUNTS command for information.
Defines the statistical errors for background data.
See the STATERRORS command for information.
Defines an expression or file to be used to specify the systematic errors for background data.
sherpa> BSYSERRORS [<dataset range> | ALLSETS] [ID] = <errorExpr>
![]() dataset range
dataset range![]()
![]() # (or more generally #:#,#:#, etc.) such that
# specifies a dataset number and #:# represents an inclusive range of datasets;
one may specify multiple inclusive ranges by separating them with
commas. The default dataset is dataset 1.
The ID modifier is used if and only if the Sherpa state
object variable multiback is set to 1, i.e., if more than
one background dataset is to be associated with a single source dataset.
The ID modifier may be any unreserved string
(e.g., A, foo, etc.), i.e.,
a string that is not a parsable command.
# (or more generally #:#,#:#, etc.) such that
# specifies a dataset number and #:# represents an inclusive range of datasets;
one may specify multiple inclusive ranges by separating them with
commas. The default dataset is dataset 1.
The ID modifier is used if and only if the Sherpa state
object variable multiback is set to 1, i.e., if more than
one background dataset is to be associated with a single source dataset.
The ID modifier may be any unreserved string
(e.g., A, foo, etc.), i.e.,
a string that is not a parsable command.
The error expression, ![]() errorExpr
errorExpr![]() , may be composed of one or
more (algebraically-combined) of the following elements:
, may be composed of one or
more (algebraically-combined) of the following elements:
| Component: | Description: |
| BACK | An input background dataset |
| numericals | Numerical values |
| operators |
A few things to note:
For additional information, see the related command BERRORS.
The background systematic errors are accessible to the Sherpa/S-Lang module user via the functions get_bsyserrors and set_bsyserrors.
Examples:
Define an expression to be used for the background systematic errors. In each bin, they will be computed as 0.1 times the background datum.
sherpa> DATA data.dat sherpa> BACK back.dat sherpa> BSYSERRORS = 0.1
Undo grouping applied to background data.
See the UNGROUP command for information.
Terminates the Sherpa program. Other equivalent termination commands are EXIT and QUIT.
sherpa> {BYE | EXIT | QUIT}
Examples:
![]() REMOVED AS OF CIAO 3.0.2
REMOVED AS OF CIAO 3.0.2![]() Casts a dataset to single or double precision.
Casts a dataset to single or double precision.
This command was removed from CIAO at version 3.0.2.
Sherpa internals have been updated to work with double-precision data only. This does not affect data entry: single-precision data are cast to double-precision, etc. The CAST command has been eliminated as it is now obsolete.
Closes the image display window.
sherpa> CLOSE IMAGE
where IMAGE is the imaging window (see the IMAGE command.)
Note: Image display windows, as well as plotting display windows, may be closed simply by closing the window with a mouse click.
See the Sherpa Chapter for further information regarding data display capabilities within Sherpa.
Examples:
Specifies the coordinate system for use in fits to 2-D images.
sherpa> COORD [<dataset range> | ALLSETS] [<arg>]
where ![]() dataset range
dataset range![]()
![]() #,
or more generally #:#,#:#,...,
such that # specifies a dataset number, and
#:# represents an
inclusive range of datasets; one may specify multiple inclusive ranges
by separating them with commas. The default dataset is dataset number 1.
#,
or more generally #:#,#:#,...,
such that # specifies a dataset number, and
#:# represents an
inclusive range of datasets; one may specify multiple inclusive ranges
by separating them with commas. The default dataset is dataset number 1.
![]() arg
arg![]() is either:
is either:
| Argument | Coordinate System |
|---|---|
| {IMAGE |
Logical coordinates: the bin numbers (1, 2, 3...) |
| PHYSICAL | Physical coordinates: a linear transformation of logical coordinates. |
| {WCS |
World coordinates (RA,dec). |
Issuing the COORD command with no argument causes Sherpa to display the current setting for the specified dataset number(s).
Note that if, e.g., a source model is defined before a switch of coordinate systems, it will be necessary either to issue the GUESS command to reset the initial parameter values and their ranges to more appropriate values, or to reset the values by hand.
Examples:
Fit data in physical coordinates:
sherpa> DATA example_img2.fits
sherpa> NOTICE FILTER "circle(425,343,30)"
sherpa> PARAMPROMPT OFF
sherpa> SOURCE = GAUSS2D[g]
sherpa> COORD
Coordinate setting for dataset 1: logical
sherpa> COORD PHYSICAL
sherpa> GUESS SOURCE
sherpa> COORD
Coordinate setting for dataset 1: physical
sherpa> g.fwhm = 1
sherpa> FIT
LVMQT: V2.0
LVMQT: initial statistic value = 1289.82
LVMQT: final statistic value = 1176.13 at iteration 12
g.fwhm 2.39494
g.xpos 4010.48
g.ypos 3927.48
g.ampl 40.3545
Computes covariance matrices, and provides an estimate of confidence intervals for selected thawed parameters.
sherpa> COVARIANCE [<dataset_range> | ALLSETS] [ <arg_1> , ... ]
where ![]() dataset range
dataset range![]()
![]() #, or more generally #:#,#:#,...,
such that # specifies a dataset number, and #:# represents an
inclusive range of datasets; one may specify multiple inclusive ranges
by separating them with commas. The default
is to estimate limits using data from all appropriate datasets.
#, or more generally #:#,#:#,...,
such that # specifies a dataset number, and #:# represents an
inclusive range of datasets; one may specify multiple inclusive ranges
by separating them with commas. The default
is to estimate limits using data from all appropriate datasets.
The command-line arguments ![]() arg_n
arg_n![]() may be:
may be:
| Argument | Description |
|---|---|
| A specified model component parameter (e.g., GAUSS.pos). | |
| A specified model component parameter (e.g., g.pos). |
The user may configure COVARIANCE via the Sherpa state object structure cov. The current values of the fields of this structure may be displayed using the command print(sherpa.cov), or using the more verbose Sherpa/S-Lang module function list_cov().
The structure field is:
| Field | Description |
|---|---|
| sigma | Specifies the number of |
Field values may be set using directly, e.g.,
sherpa> sherpa.cov.sigma = 2.6
NOTE: strict checking of value inputs is not done, i.e., the user can errantly change arrays to scalars, etc. To restore the default settings of the structure at any time, use the Sherpa/S-Lang module function restore_cov().
The confidence interval estimates are computed quickly, as described below, but are generally more accurate than those found using the command UNCERTAINTY; see also PROJECTION.
Because COVARIANCE estimates confidence intervals for each
parameter independently, the relationship
between sigma and the change in statistic value
![]() can be particularly simple:
can be particularly simple:
![]() for statistics sampled from the
for statistics sampled from the ![]() distribution and for the Cash
statistic, and is approximately equal to
distribution and for the Cash
statistic, and is approximately equal to
![]() for fits based on the general log-likelihood.
for fits based on the general log-likelihood.
| Confidence |
|
|
|
| 68.3% | 1.0 | 1.00 | 0.50 |
| 90.0% | 1.6 | 2.71 | 1.36 |
| 95.5% | 2.0 | 4.00 | 2.00 |
| 99.0% | 2.6 | 6.63 | 3.32 |
| 99.7% | 3.0 | 9.00 | 4.50 |
There are a number of computations and outputs associated with the COVARIANCE command:
First, an estimate of the information matrix is made. This is the matrix of second derivatives of the fit statistic at the best-fit point, or mode:
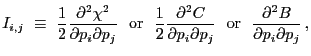 |
(1.1) |
The inverse of the information matrix provides an estimate of the covariance matrix:
| (1.2) |
Output files include the information and covariance matrices, along with
the eigenvectors and eigenvalues of the covariance matrix.
These are recorded in three temporary ASCII files in the
$ASCDS_WORK_PATH directory: ascfit.inf_matrix.![]() number
number![]() ,
ascfit.cov_matrix.
,
ascfit.cov_matrix.![]() number
number![]() , and
ascfit.eig_vector.
, and
ascfit.eig_vector.![]() number
number![]() ,
where
,
where ![]() number
number![]() refers to the process ID (pid) number for
the Sherpa run. These files may be saved by copying them
from the $ASCDS_WORK_PATH directory during the Sherpa
session. The files are deleted from the working directory when the
Sherpa session is finished.
refers to the process ID (pid) number for
the Sherpa run. These files may be saved by copying them
from the $ASCDS_WORK_PATH directory during the Sherpa
session. The files are deleted from the working directory when the
Sherpa session is finished.
One may determine if these conditions hold by plotting
the fit statistic as a function of each parameter's values (the curve should
approximate a parabola) and by examining contour plots of the fit statistics
made by varying the values of two parameters at a time (the contours
should be elliptical, and parameter space boundaries should be no closer
than approximately ![]() from the best-fit point).
from the best-fit point).
Note that these conditions are the same as those which dictate whether the use of PROJECTION will yield accurate errors. While PROJECTION is more general (e.g. allowing the user to examine the parameter space away from the best-fit point), it is in the strictest sense no more accurate than COVARIANCE for determining confidence intervals.
If either of the conditions given above does not hold, then the output from COVARIANCE may be meaningless except to give an idea of the scale of the confidence intervals. To accurately determine the confidence intervals, one would have to reparameterize the model, or use Monte Carlo simulations or Bayesian methods.
Examples:
List the current and default values of the cov structure, and restore the default values:
sherpa> sherpa.cov.sigma = 5 sherpa> list_cov() Parameter Current Default Description ---------------------------------------------------------------------- sigma 5 1 Number of sigma sherpa> restore_cov() sherpa> list_cov() Parameter Current Default Description ---------------------------------------------------------------------- sigma 1 1 Number of sigma
Determine the covariance matrix and errors for all thawed parameters:
sherpa> DATA example1a.dat
sherpa> PARAMPROMPT OFF
Model parameter prompting is off
sherpa> SOURCE = GAUSS1D[l2]
sherpa> FIT
...
sherpa> set_verbose(2)
sherpa> COVARIANCE
Information Matrix (Second Derivatives of Fit Statistic):
p.c0 p.c1 p.c2 p.c3
0.447924 1.16116 4.64118 24.2449
1.16116 4.64109 24.2449 146.113
4.64118 24.2449 146.113 954.8
24.2449 146.113 954.8 6560.89
Eigenvectors (Principal Axes) of the Covariance Matrix:
p.c0 p.c1 p.c2 p.c3
0.646594 0.747372 0.152771 0.00368201
-0.734474 0.55588 0.388661 0.0221011
0.205453 -0.361973 0.897769 0.144137
-0.0159319 0.0375378 -0.140052 0.989304
Eigenvalues of the Covariance Matrix:
159.066 3.55303 0.118346 0.000149179
Covariance Matrix (Inverse of Information Matrix):
p.c0 p.c1 p.c2 p.c3
68.4903 -74.0584 20.1862 -1.54147
-74.0584 86.9244 -24.6767 1.92902
20.1862 -24.6767 7.27528 -0.583802
-1.54147 1.92902 -0.583802 0.0478489
Covariance Matrix Determinant (Product of Eigenvalues): 0.00997785
Computed for covariance.sigma = 1
--------------------------------------------------------
Parameter Name Best-Fit Lower Bound Upper Bound
--------------------------------------------------------
p.c0 -0.303712 -8.27589 +8.27589
p.c1 0.611953 -9.32332 +9.32332
p.c2 0.790141 -2.69727 +2.69727
p.c3 0.0184866 -0.218744 +0.218744
Causes the specified 2-D data to be displayed, with a contour plot, via ChIPS.
sherpa> CPLOT [<num_plots>] <arg_1> [# [ID]] [<arg_2> [# [ID]] ...]
![]() num_plots
num_plots![]() specifies the number of plotting windows to
open within the ChIPS pane (default 1); that number sets the
number of subsequent arguments. For each subsequent argument,
# specifies the number of the dataset
(default dataset number is 1),
and the ID modifier is used for displaying background datasets,
and then if and only if
the Sherpa state
object variable multiback is set to 1,
i.e., if more than
one background dataset is to be associated with a single source dataset.
The ID modifier may be any unreserved string
(e.g., A, foo, etc.), i.e.,
a string that is not a parsable command.
specifies the number of plotting windows to
open within the ChIPS pane (default 1); that number sets the
number of subsequent arguments. For each subsequent argument,
# specifies the number of the dataset
(default dataset number is 1),
and the ID modifier is used for displaying background datasets,
and then if and only if
the Sherpa state
object variable multiback is set to 1,
i.e., if more than
one background dataset is to be associated with a single source dataset.
The ID modifier may be any unreserved string
(e.g., A, foo, etc.), i.e.,
a string that is not a parsable command.
The argument ![]() arg_n
arg_n![]() may be any of the following:
may be any of the following:
| Argument | Displays |
|---|---|
| {{DATA |
The source |
| {ERRORS |
The estimated total errors for the source |
| {SYSERRORS |
The assigned systematic errors for the source |
| {STATERRORS |
The estimated statistical errors for the source |
| {{MODEL |
The (convolved) source |
| {DELCHI |
The sigma residuals of the source |
| {RESIDUALS |
The absolute residuals of the source |
| {RATIO |
The ratio (data/model) for source |
| {CHI SQU |
The contributions to the |
| {STATISTIC |
The contributions to the current statistic
from each source |
| {WEIGHT |
The statistic weight value assigned to each source |
| {FILTER |
The mask value (0 |
| The (unconvolved) model amplitudes for the
specified model stack (SOURCE,
{BACKGROUND |
|
| The (unconvolved) model amplitudes for the specified user-defined model stack | |
| The (unconvolved) amplitudes of the specified model component (e.g., GAUSS2D) | |
| The (unconvolved) amplitudes of the specified model component (e.g., g) | |
| {EXPMAP |
The unfiltered source |
| {PSF |
The unfiltered source |
If there is no open plotting window when an CPLOT command is given, one will be created automatically.
If one issues the CPLOT following filtering,
note the following: arbitrarily
filtered data cannot be passed from Sherpa
to ChIPS for display; the data grid must be rectangular.
Therefore, contouring proceeds in three steps: (1)
the smallest possible rectangle is drawn around the noticed data;
(2) within this rectangle, the
![]() data to image
data to image![]() is tranformed to
is tranformed to
![]() data to image
data to image![]() * filter; and (3)
these transformed data are sent off to ChIPS for display.
* filter; and (3)
these transformed data are sent off to ChIPS for display.
The appearance of plots generated with this command can be changed by modifying the fields of certain state objects. See the ahelp for Sherpa or for sherpa.plot for more information.
NOTE: all ChIPS commands may be used from within Sherpa to modify plot characteristics. In order to view these changes, the REDRAW command must be issued.
See the display chapter for more information regarding data display capabilities, including modifying various plot characteristics.
Examples:
Display 2-D data with a contour plot:
sherpa> DATA 3 example2Da.dat ASCII 1 2 3 sherpa> CPLOT DATA 3
The CPLOT command plots dataset number 3 as a contour plot. Dataset number 3 must be a 2-D dataset.
Display 2-D datasets with contour plots in multiple windows:
sherpa> DATA 1 example2Db.dat ASCII 1 2 3 sherpa> CPLOT 2 DATA 1 DATA 3
This command displays a contour plot of dataset number 1 (example2Db.dat) in the first window, and a contour plot of dataset number 3 (example2Da.dat) in the second window.
Establishes a model component and its parameters, for use in the current Sherpa session.
sherpa> [CREATE] <sherpa_modelname>
(The brackets around CREATE indicate that its use is optional; see examples below.) In addition, Sherpa provides the user with the ability to both establish a model component, and to assign to it an arbitrary name:
sherpa![]()
![]() CREATE
CREATE![]()
![]() sherpa_modelname
sherpa_modelname![]()
![]()
![]() modelname
modelname![]()
![]()
where ![]() sherpa_modelname
sherpa_modelname![]() is the Sherpa default
model name (or an
XSPEC model name, with the prefix `xs' attached),
and
is the Sherpa default
model name (or an
XSPEC model name, with the prefix `xs' attached),
and ![]() modelname
modelname![]() is the name being
given to the model component by the user.
Note that
is the name being
given to the model component by the user.
Note that ![]() modelname
modelname![]() must be enclosed in brackets,
must be enclosed in brackets, ![]()
![]() .
.
Sherpa's ability to assign arbitrary names to model components allows the user to establish multiple independent models of the same type during a single session, and is a valuable feature of the software. Note that an assigned model name can be any arbitrary string, except a string that is already a Sherpa command.
By default, Sherpa will prompt the user for the initial model component parameter values. (Parameter prompting can be turned off using the command PARAPROMPT OFF.) At the model parameter prompt, the user may either:
| Argument | Description |
|---|---|
| Model parameter initial value. | |
| Minimum value for that parameter range. | |
| Maximum value for that parameter range. | |
| Specifies initial parameter step size. | |
| ,-1 | Sets the parameter to be frozen. |
Note that the default setting for delta is 1% of the parameter value. Otherwise, specifying delta will set the initial parameter step size to an absolute value. The parameter step size is used by the optimization method to determine where to sample parameter space. As such, if the value of a parameter is known well, then specifying a small delta may lead to a substantially faster and better fit.
Note that this colon separated list need not include all of the elements, but it does need to maintain the proper sequential order, and also include the colons around skipped elements. Also, there cannot be a space between the , and the -1.
The model components that have been established in the current Sherpa session, and their parameter information, may be listed with the command SHOW MODELS. Note however that information about model parameter delta settings is currently not returned by SHOW. Information about model parameter delta settings is included when using SAVE.
| For more information on: | Type: |
|---|---|
| Setting parameter values and ranges | ahelp paramset, ahelp createparamset |
| Linking parameter values | ahelp linkparam |
| Freezing and thawing model parameters | ahelp freeze, ahelp thaw |
| How parameter value estimates are made | ahelp autoest, ahelp guess |
| Controlling model integration | ahelp integrate |
| Creating model expressions | ahelp modelexpr |
| Creating model stacks | ahelp modelstack |
| Creating nested models | ahelp nestedmodels |
| Creating joint-mode models | ahelp jointmode |
Examples:
Establish a model component
sherpa> CREATE POLY POLY.c0 parameter value [1] POLY.c1 parameter value [0] POLY.c2 parameter value [0] POLY.c3 parameter value [0] POLY.c4 parameter value [0] POLY.c5 parameter value [0] POLY.c6 parameter value [0] POLY.c7 parameter value [0] POLY.c8 parameter value [0] POLY.offset parameter value [0]
The command CREATE POLY establishes the
Sherpa modelPOLY
as a model component
available for use in the current Sherpa session.
Note that after issuing this command, the user is prompted for
the initial model parameter values.
In this example, the user accepted the given initial values for
all of the parameters, using the ![]() RETURN
RETURN![]() key.
The following command is equivalent:
key.
The following command is equivalent:
sherpa> POLY
Establish a model component, and assign it a name:
sherpa> CREATE POLY[modela] modela.c0 parameter value [1] modela.c1 parameter value [0] modela.c2 parameter value [0] modela.c3 parameter value [0] modela.c4 parameter value [0] modela.c5 parameter value [0] modela.c6 parameter value [0] modela.c7 parameter value [0] modela.c8 parameter value [0] modela.offset parameter value [0]
The command CREATE POLY![]() modela
modela![]() establishes
the Sherpa model
component POLY,
and assigns to it the name modela.
Note that after issuing this command, the user is prompted for
the initial model parameter values.
In this example, the user accepted the given initial values for
all of the parameters, using the
establishes
the Sherpa model
component POLY,
and assigns to it the name modela.
Note that after issuing this command, the user is prompted for
the initial model parameter values.
In this example, the user accepted the given initial values for
all of the parameters, using the ![]() RETURN
RETURN![]() key.
The following command is equivalent:
key.
The following command is equivalent:
sherpa> POLY[modela]
Establish a model component, assign it a name, set parameter values and ranges including initial parameter step size, and freeze a parameter:
sherpa> GAUSS[modelb] modelb.fwhm parameter value [10] 2.0:1:10:0.5 modelb.pos parameter value [0] 1:0.1: modelb.ampl parameter value [1] 3::100:2,-1
This example establishes and assigns the name modelb to the Sherpa model component GAUSS1D. Note that in this example the user entered an initial value of 2.0, a minimum range value of 1, a maximum range value of 10, and an initial parameter step size delta of 0.5 for parameter fwhm; entered a value of 1, and a minimum range value of 0.1 for parameter pos; and entered a value of 3, a maximum range value of 100, and an initial parameter step size of 2 for parameter ampl, and froze this parameter.
Establish a model component, assign it a name, set parameter values and ranges, and freeze a parameter:
sherpa> GAUSS[modelbb] modelbb.fwhm parameter value [10] 2.0:1:10 modelbb.pos parameter value [0] 1:0.1: modelbb.ampl parameter value [1] 3::100,-1
This example establishes and assigns the name modelb to the Sherpa model component GAUSS1D. Note that in this example the user entered an initial value of 2.0, a minimum range value of 1, and a maximum range value of 10 for parameter fwhm; entered a value of 1, and a minimum range value of 0.1 for parameter pos; and entered a value of 3, and a maximum range value of 100 for parameter ampl, and froze this parameter (note that after the maximum range value, specification of initial parameter step size delta is optional and may be omitted).
Establish an XSPEC model component, assign it a name, and freeze a parameter:
sherpa> XSBBODY[modeld] modeld.kT parameter value [3] modeld.norm parameter value [1] ,-1
This command establishes and assigns the name modeld to the
XSPEC model component
bbody.
In this example, the user
accepted the given initial values for all of the parameters, using
the ![]() RETURN
RETURN![]() ,
and set parameter norm to be frozen.
,
and set parameter norm to be frozen.
Turn off model parameter prompting; establish a model component and assign it a name:
sherpa> PARAMPROMPT OFF Model parameter prompting is off sherpa> POW[modelc]
The first command turns off prompting for model parameter values. The second command establishes the Sherpa model component POW, and assigns to it the name modelc. Since parameter prompting was turned off, the model is automatically established using the given initial values for all of the parameters.
Establish two independent model components of the same type:
sherpa> ERASE ALL sherpa> PARAMPROMPT ON Model parameter prompting is on sherpa> POW[modelc] modelc.gamma parameter value [0] 1.0 modelc.ref parameter value [1] modelc.ampl parameter value [1] sherpa> POW[modelc2] modelc2.gamma parameter value [0] 2.0 modelc2.ref parameter value [1] modelc2.ampl parameter value [1]
The third command establishes the Sherpa model component POWLAW1d, and assigns to it the name modelc. In this example, the user set parameter gamma of model component modelc to the value of 1.0. The last command establishes another Sherpa model component POWLAW1d, and assigns to it the name modelc2. In this example, the user set parameter gamma of model component modelc2 to the value of 2.0. Note that model components modelc and modelc2 are independent of one another.
Inputs the contents of one or more source data files.
sherpa> DATA [#] <filespec> [, [#] <filespec>,...]
where # specifies the number of the dataset to be associated with this source data file (default dataset number is 1).
Alternative means of reading in source datasets involve using the load functions of the Sherpa/S-Lang module (e.g., load_pha).
The help file for the READ command explains the ![]() filespec
filespec![]() definition and has a listing of allowed file types; see also the related
commands SOURCE, ERRORS, and SETDATA.
definition and has a listing of allowed file types; see also the related
commands SOURCE, ERRORS, and SETDATA.
unix% dmcopy "infile.fits[spec 1][spec 2]" outfile.fits
you can also do
sherpa> data "infile.fits[spec 1][spec 2]"
This is especially useful when working with very large files. For example:
sherpa> data "evt.fits[bin sky=4][opt mem=100]"
bins the event file by a factor of four and allocates additional memory. A similar command (omitting the binning factor) can be used to read in an image.
Examples:
Input an ASCII data file having a .dat extension name:
sherpa> DATA example.dat
This command reads the first two columns of the ASCII data file example.dat, as dataset number 1.
Input an ASCII data file not having a .dat extension name:
sherpa> DATA example.qdp ASCII 1 2
This command reads columns 1 and 2 of the ASCII data file example.qdp, as dataset number 1.
Input a FITS image data file:
sherpa> DATA 3 data/example_img.fits FITS
This command reads the FITS image data/example_img.fits,as dataset number 3.
Creates a data grid on which models may be evaluated.
sherpa> DATASPACE [#] (<range> [, <range>, ...]) [HISTOGRAM]
where # specifies the number of the dataset to be associated with
the dataspace (default dataset number is 1); ![]() range
range![]() is defined
below; and HISTOGRAM
tells Sherpa to define bins (with lower and upper
boundaries) rather than single gridpoints.
is defined
below; and HISTOGRAM
tells Sherpa to define bins (with lower and upper
boundaries) rather than single gridpoints.
![]() range
range![]()
![]()
![]() start
start![]() :
:![]() stop
stop![]() :
:![]() delta
delta![]() , where
, where
| Argument | Definition |
|---|---|
| The start (minimum) value for the grid. | |
| The stop (maximum) value for the grid. | |
| The step size between gridpoints. |
If HISTOGRAM is specified, the models will be evaluated
by integrating over bins of width ![]() delta
delta![]() ; otherwise,
models will be evaluated at points on the specified grid.
; otherwise,
models will be evaluated at points on the specified grid.
Note: HISTOGRAM must be specified in order to evaluate XSPEC models additive models (e.g., xsbremss).
A dataspace may also be defined using the Sherpa/S-Lang module functions set_axes and set_baxes. (In CIAO 3.0, set_baxes is the only means by which background dataspaces may be defined.)
Examples:
Set a 1-D value range on which a source model may be evaluated:
sherpa> DATASPACE (1:5:1)
This command sets the value range, from values 1 through 5, with a step-size of 1, over which a source model may be evaluated.
Set a 2-D value range on which a source model may be evaluated:
sherpa> DATASPACE (1:5:1,1:2:1)
This command sets the value ranges, for two dimensions, over which a source model may be evaluated.
Set a 1-D value range on which a source model may be evaluated, for dataset number 2:
sherpa> DATASPACE 2 (1:10:1)
This command sets the value range, from values 1 through 10, with a step-size of 1, over which a source model may be evaluated, for dataset number 2.
Turns on/off reporting of user keystrokes.
sherpa> ECHO {ON | OFF}
The ECHO command can be used to create a log of an entire session - including screen output - when run from a script.
By default, reporting of user keystrokes is turned off.
Examples:
Turn on reporting of user keystrokes; turn off reporting of user keystrokes:
sherpa> PARAMPROMPT OFF Model parameter prompting is off sherpa> ECHO ON Echo is on ECHO ON sherpa> POLY[modela] POLY [ modela ] sherpa> ECHO OFF Echo is off sherpa> GAUSS[modelb] sherpa>
Calculates the unconvolved energy flux for source or background datasets.
sherpa> [B]EFLUX [# [ID]] [{(<value>) | (<min>:<max>) | (<region descriptor>)} ] \
[ {(<model component>) | (<model stack>)} ]
EFLUX is used for computing source energy fluxes, while BEFLUX is used for computing background energy fluxes.
# specifies the dataset over which the source model is evaluated. The ID modifier is used only for computing background fluxes, and then if and only if the Sherpa state object variable multiback is set to 1, i.e., if more than one background dataset is to be associated with a single source dataset. The ID modifier may be any unreserved string (e.g., A, foo, etc.), i.e., a string that is not a parsable command.
The default is to compute energy fluxes for all appropriate datasets (i.e., those for which source/background expressions have been defined). The flux may be computed at one energy/wavelength, over a range of energies/wavelengths, or within a 2-D region, with the default being to compute the flux the total available range.
The flux may also be computed for individual model components, or for previously defined model stacks, with the default being to compute the flux using all model components in the SOURCE or BACKGROUND expression.
A source or background model stack must be defined before a respective flux can be computed; see the SOURCE and BACKGROUND commands. This is true even if one computes the flux of an individual model component or of models defined in a model stack. (This limitation will be removed in a future version of Sherpa.)
For 1-D data, if:
For 1-D data, if an instrument model is not used, the units are (perhaps incorrectly) assumed to be counts, or counts per bin-width. See the Note on Units below.
For 2-D data, if a region descriptor is given, then the total integrated energy flux within that region is returned; otherwise, the integration is carried out over the entire input image.
Note on Units: In its current incarnation, Sherpa has no explicit knowledge of data or model units. The units displayed with computed fluxes are defaults, generally correct for standard analyses of 1-D PHA energy/wavelength spectra (XSPEC-like analyses). They may be incorrect for non-standard analyses, or for analyses of 2-D spatial images with exposure maps, etc. The correct units can be determined by working backwards from the data, taking into account the exposure time, the units of the instrument model, the bin units, etc.
Tip: To perform background subtraction in Sherpa, the command SUBTRACT must be issued; this is in contrast to XSPEC, which performs background subtraction automatically.
The energy flux may be computed using the Sherpa/S-Lang module functions get_eflux and get_beflux.
Examples:
Calculate the integrated energy flux over the full energy range:
sherpa> EFLUX Flux for source dataset 1: 1.94551e-13 ergs/cm**2/s
Calculate the integrated background photon flux over the range 2 to 10 keV:
sherpa> BEFLUX (2.0:10.0) Flux for background dataset 1: 3.59906e-13 ergs/cm**2/s
Calculate the energy flux at a single energy (2.0 keV) for the power-law component of a source expression:
sherpa> SOURCE 1 = XSWABS[A] * POW[P] sherpa> EFLUX 1 (2.0) P Flux for source dataset 1: 1.73452e-14 ergs/cm**2/s/keV
Calculate the total energy flux over the energy range 2.0 to 4.0 keV for a model stack:
sherpa> FOO = POW[P] + GAUSS[G] sherpa> SOURCE 1 = XSWABS[A] * FOO sherpa> EFLUX 1 (2:4) FOO Flux for source dataset 1: 2.46491e-13 ergs/cm**2/s
Computes the equivalent width of an emission or absorption line in source or background data.
sherpa> [B]EQWIDTH [# [ID]] (<continuum_stack>, <continuum_plus_line_stack>)
EQWIDTH is used for computing equivalent widths in source datasets, while BEQWIDTH is used for computing equivalent widths in background datasets.
# specifies the dataset over which the source model is evaluated. The ID modifier is used only for computing background dataset equivalent widths, and then if and only if the Sherpa state object variable multiback is set to 1, i.e., if more than one background dataset is to be associated with a single source dataset. The ID modifier may be any unreserved string (e.g., A, foo, etc.), i.e., a string that is not a parsable command.
![]() continuum_stack
continuum_stack![]() represents one or more models (or
user-defined model stacks) that describe the continuum, while
represents one or more models (or
user-defined model stacks) that describe the continuum, while
![]() continuum_plus_line_stack
continuum_plus_line_stack![]() represents two or more models (or user-defined model stacks)
that describe the continuum plus line.
represents two or more models (or user-defined model stacks)
that describe the continuum plus line.
To compute the equivalent width, an integral
over the energy/wavelength range of the dataset is performed.
At each point,
the ![]() continuum_stack
continuum_stack![]()
![]() and
and ![]() continuum_plus_line_stack
continuum_plus_line_stack![]()
![]() are evaluated;
the integrand is then
are evaluated;
the integrand is then
![]() .
.
The models are specified on-the-fly in the same manner that
SOURCE or
BACKGROUND model
stacks are defined, as algebraic combinations of previously defined
model components. The examples below illustrate this point.
The user must specify the models in this manner, because
(a) Sherpa cannot identify
whether a particular model component should be associated with
the continuum or with the line, and (b) multiple line components
may be specified in the SOURCE model stack, so that
it cannot be used in place of
![]() continuum_plus_line_stack
continuum_plus_line_stack![]() to compute equivalent widths.
to compute equivalent widths.
Equivalent widths may also be computed using the Sherpa/S-Lang module functions get_eqwidth and get_beqwidth.
Examples:
Model a continuum and emission line complex using a power-law and normalized Gaussian, then compute the equivalent width:
sherpa> SOURCE = POW[cont]+NGAUSS[eline] ... sherpa> FIT ... sherpa> EQWIDTH 1 (cont,cont+eline) EW = 0.535073 keV
Define continuum and line model stacks; use these in the equivalent width calculation:
sherpa> BBODY[modela] sherpa> POWLAW1D[modelb] sherpa> NGAUSS[line1] sherpa> NGAUSS[line2] sherpa> NGAUSS[line3] ... sherpa> CONT = modela+modelb sherpa> ELINE = line1 sherpa> SOURCE = CONT + ELINE + line2 + ... sherpa> FIT ... sherpa> EQWIDTH 1 (CONT,CONT+ELINE) EW = 0.454946 keV
Erases user inputs and settings, and/or model components.
sherpa> ERASE [{ALL | <sherpa_modelname> | <modelname> |
<model_stack> | DATA [#] | BACK [# [ID]]}]
where # specifies the number of the dataset to be erased (default dataset number is 1). The ID modifier is used if and only if the Sherpa state object variable multiback is set to 1, i.e., if more than one background dataset is to be associated with a single source dataset. The ID modifier may be any unreserved string (e.g., A, foo, etc.), i.e., a string that is not a parsable command.
ERASE ALL causes the following to be erased from the current Sherpa session:
Note that ERASE ALL does not cause the optimization method, statistic choice, parameter prompting, or variables within the state object to be reset to default values. RESET is a related command that may be used to restore program settings and parameter values.
ERASE
![]() sherpa_modelname
sherpa_modelname![]() and ERASE
and ERASE
![]() modelname
modelname![]() cause the specified single model component to be erased.
Note, however, that a single component cannot be erased if it is
part of a model stack definition (e.g.,
SOURCE).
Clear the stack first (by issuing, e.g.,
the command SOURCE
cause the specified single model component to be erased.
Note, however, that a single component cannot be erased if it is
part of a model stack definition (e.g.,
SOURCE).
Clear the stack first (by issuing, e.g.,
the command SOURCE ![]() ), then issue the
ERASE command.
), then issue the
ERASE command.
ERASE ![]() model_stack
model_stack![]() causes the specified
single user-defined model stack to be removed; like above, it cannot
be erased if it is part of another stack's definition.
causes the specified
single user-defined model stack to be removed; like above, it cannot
be erased if it is part of another stack's definition.
Examples:
Remove a model component:
sherpa> DATA example.dat
sherpa> PARAMPROMPT OFF
Model parameter prompting is off
sherpa> POW[modelc]
sherpa> SHOW
Current Data Files:
Data 1: data/example.dat ascii 1 2.
Total Size: 4 bins (or pixels)
Dimensions: 1
Total counts (or values): 31
Optimization Method: Powell
Statistic: Chi-Squared Gehrels
Current Models are:
Current Composite Models are:
Current Model Components are:
powlaw1d[modelc] (integrate: on)
Param Type Value Min Max Units
----- ---- ----- --- --- -----
1 gamma thawed 1 -10 10
2 ref frozen 1 1 4
3 ampl thawed 3 0.0300 300
sherpa> ERASE modelc
In this example, a dataset is input and a model component called modelc is established. The ERASE command then removes this model component.
Erase a background dataset:
sherpa> DATA example2.pha ... Background data are being input from: <directory path>/example2_bkg.pha sherpa> SHOW ... ----------------- Input data files: ----------------- Data 1: example2.pha pha. ... Background 1: <directory path>/example2_bkg.pha pha. ... sherpa> ERASE BACK sherpa> SHOW ... ----------------- Input data files: ----------------- Data 1: example2.pha pha. ... sherpa>
In this example, the background dataset was automatically loaded into Sherpa because the source dataset PHA file contained the header keyword BACKFILE.
Remove all user inputs and user-defined settings:
sherpa> METHOD GRID sherpa> STATISTIC BAYES sherpa> ERASE ALL sherpa> SHOW Current Data Files: Optimization Method: Grid Statistic: Bayes Current Models are: Current Composite Models are: Current Model Components are:
This example illustrates that ERASE ALL does not return either the optimization method or the statistic to the default setting (the default method is LEVENBERG-MARQUARDT; the default statistic is CHI GEHRELS).
Defines an expression to be used to specify the statistical errors for source data.
sherpa> ERRORS [<dataset range> | ALLSETS] = <errorExpr>
where ![]() dataset range
dataset range![]()
![]() #,
or more generally #:#,#:#,...,
such that
#
specifies a dataset number, and #:#
represents an inclusive range of datasets;
one may specify multiple inclusive ranges by separating them
with commas. The default dataset is dataset 1.
#,
or more generally #:#,#:#,...,
such that
#
specifies a dataset number, and #:#
represents an inclusive range of datasets;
one may specify multiple inclusive ranges by separating them
with commas. The default dataset is dataset 1.
The error expression, ![]() errorExpr
errorExpr![]() , may be composed of one, or
more (algebraically-combined) of the following elements:
, may be composed of one, or
more (algebraically-combined) of the following elements:
| Component: | Description: |
|---|---|
| DATA | An input dataset |
| numericals | Numerical values |
| operators |
A few things to note:
See the related command SYSERRORS.
The errors are accessible to the Sherpa/S-Lang module user via the functions get_errors and set_errors.
Examples:
Define an expression to be used for the errors. They are set to one-half of the data value in each bin.
sherpa> DATA example.dat sherpa> ERRORS = (0.5)*(DATA)
Define an expression to be used for the errors. They are set to be the sum of the datum and 2.7 in each bin.
sherpa> DATA example.dat sherpa> ERRORS 1 = DATA + 2.7
Terminates the Sherpa program.
See the BYE command.
Creates a simulated 1-D dataset.
sherpa> FAKEIT [#]
# specifies the number of the dataset to be simulated (default dataset number is 1).
The FAKEIT command creates a simulated 1- or 2-D dataset. It cannot be successfully issued without first:
The user may define the grid in one of three ways:
If one defines a dataspace and plans to use XSPEC models, then one must use the HISTOGRAM modifier to the DATASPACE command, since XSPEC models expect the dataset to be binned. Otherwise, the simulated data set may be either binned or unbinned.
Other, optional information may be input before FAKEIT is run.
Values of the FAKEIT parameters may be set as follows:
sherpa> FAKEIT TIME = <time> sherpa> FAKEIT BACKSCALE = <backscale>
where ![]() time
time![]() is in seconds,
is in seconds,
![]() backscale
backscale![]() is a dimensionless number.
is a dimensionless number.
Background data and/or models are treated as follows in FAKEIT:
FAKEIT creates a new dataset
and keeps it in memory (the Sherpa number assigned to
this dataset is
specified with # in the FAKEIT command).
This new dataset may then be treated as though it were a dataset that
the user had read from a file (e.g., it may be plotted using the
LPLOT DATA ![]() #
#![]() command; it may be used in a fit,
etc.).
Note that if the user has previously read a dataset,
it will be overwritten with the new dataset created by
FAKEIT.
command; it may be used in a fit,
etc.).
Note that if the user has previously read a dataset,
it will be overwritten with the new dataset created by
FAKEIT.
Note that in CIAO 3.0, there is no facility for faking background spectra (i.e., there is no BFAKEIT command).
Examples:
Simulate a dataset, with an instrument model:
sherpa> RSP[instrumentA](data/example2.rmf,data/example2.arf) The inferred file type is ARF. If this is not what you want, please specify the type explicitly in the data command. sherpa> INSTRUMENT = instrumentA
The above commands define an instrument model named instrumentA, using the RMF and ARF files data/example2.rmf and data/example2.arf respectively. Next, a background data file is input:
sherpa> BACK data/example2_bkg.pha The inferred file type is PHA. If this is not what you want, please specify the type explicitly in the data command.
The FAKEIT parameters are then set:
sherpa> FAKEIT TIME = 33483.2 sherpa> FAKEIT BACKSCALE = 0.0441895 sherpa> SHOW FAKEIT Fakeit exposure time: 33483.2 seconds. Fakeit backscale: 0.0441895
And, a simple source model expression is defined:
sherpa> PARAMPROMPT OFF Model parameter prompting is off sherpa> SOURCE = POW[modela] sherpa> modela.gamma=2 sherpa> modela.ampl.min=0.000001 sherpa> modela.ampl=0.0003 sherpa> modela.ref=1
Finally, a simulated dataset is created:
sherpa> FAKEIT FAKEIT: The current background data have been added to the faked spectrum.
This simulated dataset may be plotted, and written as PHA and ASCII files:
sherpa> LPLOT DATA sherpa> WRITE DATA sim1.pha PHA Write X-Axis: Energy (keV) Y-Axis: Counts sherpa> WRITE DATA sim1.dat ASCII Write X-Axis: Energy (keV) Y-Axis: Flux (Counts/sec/keV)
Simulate a dataset, utilizing a previously input PHA file:
sherpa> ERASE ALL
sherpa> DATA data/example2.pha
The inferred file type is PHA. If this is not what you want, please
specify the type explicitly in the data command.
WARNING: using systematic errors specified in the PHA file.
RMF is being input from:
<directory_path>/example.rmf
ARF is being input from:
<directory_path>/example.arf
Background data are being input from:
<directory_path>/example_bkg.pha
sherpa> SHOW
Optimization Method: Levenberg-Marquardt
Statistic: Chi-Squared Gehrels
-----------------
Input data files:
-----------------
Data 1: example2.pha pha.
Total Size: 95 bins (or pixels)
Dimensions: 1
Total counts (or values): 1688
Exposure: 33483.25 sec
Count rate: 0.050 cts/sec
Backscal: 0.044189
Background 1: /data/simteste/Testing/sherpaTest/data/example2_bkg.pha pha.
Total Size: 512 bins (or pixels)
Dimensions: 1
Total counts (or values): 2220
Exposure: 108675.66 sec
Count rate: 0.020 cts/sec
Backscal: 0.044189
The data are NOT background subtracted.
------------------------------
Defined analysis model stacks:
------------------------------
instrument source 1 = AutoReadResponse
instrument back 1 = AutoReadResponse
------------------------------------
Defined instrument model components:
------------------------------------
rsp1d[AutoReadResponse]
Param Type Value Min Max Units
----- ---- ----- --- --- -----
1 rmf string: "/data/simteste/Testing/sherpaTest/data/example2.rmf"
2 arf string: "/data/simteste/Testing/sherpaTest/data/example2.arf"
sherpa> SHOW FAKEIT
Fakeit exposure time: 33483.2 seconds.
Fakeit backscale: 0.0441895
After inputting a PHA dataset, the SHOW command confirms that an instrument model has been automatically defined using RMF and ARF files. Also, a background data file has been automatically read. The SHOW FAKEIT command confirms that the input data file contained the exposure time, backscale, and areascale keywords pertinent to the observation. Next, a source model expression is defined, and then a simulated dataset is created and written:
sherpa> PARAMPROMPT OFF Model parameter prompting is off sherpa> SOURCE = POW[modelA] sherpa> modelA.gamma=2 sherpa> modelA.ampl.min=0.000001 sherpa> modelA.ampl=0.0003 sherpa> modelA.ref=1 sherpa> FAKEIT FAKEIT: The current background data have been added to the faked spectrum. sherpa> WRITE DATA simA.pha PHA Write X-Axis: Energy (keV) Y-Axis: Counts
Simulate a second dataset:
sherpa> RSP[instrumentB](data/example2.rmf,data/example2.arf) The inferred file type is ARF. If this is not what you want, please specify the type explicitly in the data command. sherpa> INSTRUMENT 2 = instrumentB sherpa> BACK 2 data/example2_bkg.pha The inferred file type is PHA. If this is not what you want, please specify the type explicitly in the data command. sherpa> FAKEIT 2 TIME = 66966.4 sherpa> FAKEIT 2 BACKSCALE = 0.0441895 sherpa> SOURCE 2 = POW[modelB] sherpa> modelB.gamma=2 sherpa> modelB.ampl.min=0.000001 sherpa> modelB.ampl=0.0003 sherpa> modelB.ref=1 sherpa> FAKEIT 2 FAKEIT: The current background data have been added to the faked spectrum. sherpa> LPLOT 2 DATA 1 DATA 2 sherpa> WRITE DATA 2 fakeit3.pha PHA Write X-Axis: Energy (keV) Y-Axis: Counts
These commands define a second instrument model, input a background data file for dataset number 2, set the FAKEIT parameters for dataset number 2, and define a second source model. The command FAKEIT 2 then creates simulated dataset number 2. Both simulated datasets are then plotted, and the second dataset is written to the data file fakeit3.pha.
Simulate a dataset, without an instrument model:
sherpa> ERASE ALL sherpa> PARAMPROMPT OFF Model parameter prompting is off sherpa> SOURCE = POW[modela] sherpa> DATASPACE (1:1000:2) sherpa> FAKEIT TIME = 33483.2 sherpa> FAKEIT BACKSCALE = 0.0441895 sherpa> SHOW FAKEIT Fakeit exposure time: 33483.2 seconds. Fakeit backscale: 0.0441895 sherpa> modela.gamma=2 sherpa> modela.ampl.min=0.000001 sherpa> modela.ampl=0.0003 sherpa> modela.ref=1 sherpa> FAKEIT sherpa> LPLOT DATA
Instead of defining an instrument model, the DATASPACE command is used to define the appropriate grid over which to calculate the model values.
Fake a 2-D image:
sherpa> DATASPACE (1:256:1,1:256:1) sherpa> PARAMPROMPT OFF sherpa> INSTRUMENT = FPSF2D[p] sherpa> p.file = psf.fits sherpa> SOURCE = GAUSS2D[g] sherpa> g.xpos = 128 sherpa> g.ypos = 128 sherpa> g.ampl = 100 sherpa> g.fwhm = 25 sherpa> FAKEIT
Specifies the Fits Embedded Function (FEF) file whose contents will be displayed with FEFPLOT.
sherpa> FEFFILE "<filename>[<virtual_file_syntax>]"
where ![]() virtual_file_syntax
virtual_file_syntax![]() is an optional filtering and/or binning command argument.
Note that, whenever
is an optional filtering and/or binning command argument.
Note that, whenever ![]() virtual_file_syntax
virtual_file_syntax![]() is specified,
is specified,
![]() filename
filename![]()
![]() virtual_file_syntax
virtual_file_syntax![]() must be surrounded by quotes, " ".
must be surrounded by quotes, " ".
See FEFPLOT for more information, and further examples.
Examples:
Read in a part of a FEF file using a ![]() virtual_file_syntax
virtual_file_syntax![]() filter expression:
filter expression:
sherpa> FEFFILE "data/fef_response.fits[function][ccd_id=0,chipx>=1,chipx<=256,chipy>=1,chipy<=32]"
Plots an instrument response stored in a Fits Embedded Function (FEF) file that is read in via FEFFILE.
sherpa> FEFPLOT {<photon_energy> | <photon_wavelength>}
where {![]() photon_energy
photon_energy![]()
![]()
![]() photon_wavelength
photon_wavelength![]() }
must be in the same units that are used
for photon energies in the FEF file (conventionally, keV or Angstroms).
}
must be in the same units that are used
for photon energies in the FEF file (conventionally, keV or Angstroms).
Examples:
Read in part of a FEF file and plot the response as a function of counts-space energy, at photon energy 2.4 keV:
sherpa> FEFFILE "data/fef_response.fits[function][ccd_id=0,chipx>=1,chipx<=256,chipy>=1,chipy<=32]" sherpa> FEFPLOT 2.4
The appearance of the plot may be subsequently altered using ChIPS commands such as:
sherpa> LIMITS X 0 3 sherpa> REDRAW
Initiates fitting (optimization). The command ![]() B
B![]() RUN is equivalent.
RUN is equivalent.
sherpa> {[B]FIT | [B]RUN} [<dataset range> | ALLSETS] [ID]
FIT and RUN are used in initiate fitting of all appropriate source and background datasets (i.e., those for which SOURCE and/or BACKGROUND model stacks have been defined), while BFIT and BRUN are used to initiate fitting of appropriate background datasets only.
![]() dataset range
dataset range![]()
![]() # (or more generally #:#,#:#, etc.) such that
# specifies a dataset number and #:# represents an inclusive range of datasets;
one may specify multiple inclusive ranges by separating them with
commas. The default is to fit all appropriate datasets.
The ID modifier is used if and only if the Sherpa state
object variable multiback is set to 1, i.e.,
if more than
one background dataset is to be associated with a single source dataset.
The ID modifier may be any unreserved string
(e.g., A, foo, etc.), i.e.,
a string that is not a parsable command.
# (or more generally #:#,#:#, etc.) such that
# specifies a dataset number and #:# represents an inclusive range of datasets;
one may specify multiple inclusive ranges by separating them with
commas. The default is to fit all appropriate datasets.
The ID modifier is used if and only if the Sherpa state
object variable multiback is set to 1, i.e.,
if more than
one background dataset is to be associated with a single source dataset.
The ID modifier may be any unreserved string
(e.g., A, foo, etc.), i.e.,
a string that is not a parsable command.
In CIAO 3.1 the definition of INSTRUMENT BACK is required for fitting PHA data if either background file or background models have been defined. INSTRUMENT BACK is set automatically when the PHA data file is input to Sherpa, however it is deleted if the NEW background file is input for a given data set. Thus the new INSTRUMENT BACK has to be defined on the command line before starting a simultaneous fit with the new background file.
Fitting may also be initiated via the Sherpa/S-Lang module function run_fit. (This is equivalent to FIT; there is no module function equivalent of BFIT in CIAO 3.0.)
Examples:
Fit a source model to one dataset:
sherpa> READ DATA 1 example1.dat sherpa> PARAMPROMPT OFF Model parameter prompting is off sherpa> POLY[modela] sherpa> SOURCE 1 = modela sherpa> THAW modela.2 modela.3 sherpa> FIT
The fourth command, SOURCE 1 ![]() modela, defines the
Sherpa model POLY as the source model to be used
for fitting dataset number 1.
The last command, FIT,
fits source model number 1 to its corresponding dataset.
For this example, the following command is equivalent to the last command:
modela, defines the
Sherpa model POLY as the source model to be used
for fitting dataset number 1.
The last command, FIT,
fits source model number 1 to its corresponding dataset.
For this example, the following command is equivalent to the last command:
sherpa> FIT 1
Fit a source model to one dataset, when multiple source models have been defined:
sherpa> ERASE ALL sherpa> READ DATA 1 example1.dat sherpa> POLY[modela] sherpa> GAUSS[modelb] sherpa> SOURCE 1 = modela sherpa> SOURCE 2 = modelb sherpa> THAW modela.2 modela.3 sherpa> FIT 1
The last command fits source model number 1 to its corresponding dataset. Note that source model number 2 does not have a corresponding dataset, and so no fitting for this model will be performed; thus for this example, the following command is equivalent to the last command:
sherpa> FIT
Fit a source model to one dataset, when multiple source models have been defined and multiple datasets have been input:
sherpa> ERASE ALL sherpa> READ DATA 1 example1.dat sherpa> READ DATA 2 example2.dat sherpa> POLY[modela] sherpa> GAUSS[modelb] sherpa> SOURCE 1 = modela sherpa> SOURCE 2 = modelb sherpa> THAW modela.2 modela.3 sherpa> FIT 1
The last command fits source model number 1 to its corresponding dataset. Note that source model number 2 is not fit to its corresponding dataset, because only source model number 1 is specified in the FIT command. In this example, the following commands could be issued to fit source model number 2 to its corresponding dataset:
sherpa> GUESS SOURCE 2 sherpa> FIT 2
Note that the GUESS SOURCE 2 command is issued, in order to start the initial parameter values and ranges, of source model number 2, at estimates based on the input dataset number 2. See the GUESS command for futher information.
Independently fit the same model shape to different datasets:
sherpa> ERASE ALL sherpa> READ DATA 1 example1.dat sherpa> READ DATA 2 example2.dat sherpa> POLY[modela] sherpa> POLY[modelb] sherpa> SOURCE 1 = modela sherpa> SOURCE 2 = modelb sherpa> THAW modela.2 modela.3 sherpa> THAW modelb.2 modelb.3 sherpa> GUESS SOURCE 2 sherpa> FIT
The last command fits source model number 1 to its corresponding dataset (dataset number 1), and fits source model number 2 to its corresponding dataset (dataset number 2). In this example, source models 1 and 2 are the same model, but with separate and independent parameters. The GUESS SOURCE 2 command is issued in order to start the initial parameter values and ranges, of source model number 2, at estimates based on the input dataset number 2. See the GUESS command for futher information. For this example, the following commands are equivalent to the last command:
sherpa> FIT 1,2 sherpa> FIT 1:2 sherpa> FIT ALLSETS
Perform a joint fit of two datasets using the same source model:
sherpa> ERASE ALL sherpa> READ DATA 1 example1.dat sherpa> READ DATA 2 example2.dat sherpa> POLY[modela] sherpa> SOURCE 1:2 = modela sherpa> THAW modela.2 modela.3 sherpa> FIT
The last command fits source model number 1 to its corresponding dataset (dataset number 1), and fits source model number 2 to its corresponding dataset (dataset number 2). In this example, source models 1 and 2 are the same model, with shared parameters. For this example, the following commands are equivalent to the last command:
sherpa> FIT 1,2 sherpa> FIT 1:2 sherpa> FIT ALLSETS
Note that in this example, the command FIT 1 would have fit the source model only to dataset number 1; the command FIT 2 would have fit the source model only to dataset number 2.
Independently fit the same model shape to different datasets, but link one source model parameter to another:
sherpa> ERASE ALL sherpa> READ DATA 1 example1.dat sherpa> READ DATA 2 example2.dat sherpa> POLY[modela] sherpa> POLY[modelb] sherpa> SOURCE 1 = modela sherpa> SOURCE 2 = modelb sherpa> modelb.c0 => modela.c0 sherpa> THAW modela.2 modela.3 sherpa> FIT
The last command fits source model number 1 to its corresponding dataset (dataset number 1), and fits source model number 2 to its corresponding dataset (dataset number 2). In this example, source models 1 and 2 are the same model, but with separate and independent parameters, for all parameters except c0. Parameter c0 is a shared parameter, as set by the parameter expression, in the eighth command (see the CREATE command for further information on model parameter expressions). For this example, the following commands are equivalent to the last command:
sherpa> FIT 1,2 sherpa> FIT 1:2 sherpa> FIT ALLSETS
Perform a joint fit of some (but not all) input datasets using the same source model:
sherpa> ERASE ALL sherpa> READ DATA 1 example1.dat sherpa> READ DATA 2 example2.dat sherpa> READ DATA 3 example3.dat sherpa> READ DATA 4 example4.dat sherpa> POLY[modela] sherpa> SOURCE 1 = modela sherpa> SOURCE 2 = modela sherpa> SOURCE 3 = modela sherpa> SOURCE 4 = modela sherpa> THAW modela.2 modela.3 sherpa> FIT 2,3
The last command fits source model number 2 to its corresponding dataset (dataset number 2), and fits source model number 3 to its corresponding dataset (dataset number 3). In this example, source models 2 and 3 are the same model, with shared parameters. Note that because source models 1 through 4 are all the same model, with shared parameters, one may specify to simultaneously fit to any of the input datasets. The command
sherpa> FIT 1,4
fits the source model to datasets number 1 and 4. The command
sherpa> FIT 2:4
(or FIT 2,3,4) fits the source model to datasets number 2, 3, and 4. The command
sherpa> FIT 1:4
(or FIT 1,2,3,4, or FIT, or FIT ALLSETS) fits the source model to all of the input datasets.
Perform a fit to a background dataset:
sherpa> READ DATA 1 example1.dat sherpa> READ BACK 1 example1_back.dat sherpa> SOURCE 1 = POLY[modela] sherpa> BACKGROUND 1 = POLY[modelb] sherpa> BFIT 1
The command BFIT instructs Sherpa to fit modelb to the input background data only, ignoring the source data and source model stack. For this example, the following commands are equivalent to the last command:
sherpa> BFIT
or
sherpa> SOURCE 1 = sherpa> FIT 1 # or simply FIT
Calculates the unconvolved photon flux for source or background datasets.
sherpa> [B][P]FLUX [# [ID]] [{(<value>) | (<min>:<max>) | (<region descriptor>)} ] \
[ {(<model component>) | (<model stack>)} ]
FLUX and PFLUX are equivalent commands for computing source fluxes, while BFLUX and BPFLUX are equivalent commands for computing background fluxes.
# specifies the dataset over which the model is evaluated. The ID modifier is used only for computing background fluxes, and then if and only if the Sherpa state object variable multiback is set to 1, i.e., if more than one background dataset is to be associated with a single source dataset. The ID modifier may be any unreserved string (e.g., A, foo, etc.), i.e., a string that is not a parsable command.
The default is to compute photon fluxes for all appropriate datasets (i.e., those for which source/background expressions have been defined). The flux may be computed at one energy/wavelength, over a range of energies/wavelengths, or within a 2-D region, with the default being to compute the flux the total available range.
The flux may also be computed for individual model components, or for previously defined model stacks, with the default being to compute the flux using all model components in the SOURCE or BACKGROUND expression.
Note that FLUX computes only photon fluxes in CIAO 3.0; to compute energy fluxes, use EFLUX, while to compute summations of observed or model counts, use DCOUNTS and MCOUNTS, respectively.
A source or background model stack must be defined before a respective flux can be computed; see the SOURCE and BACKGROUND commands. This is true even if one computes the flux of an individual model component or of models defined in a model stack. (This limitation will be removed in a future version of Sherpa.)
For 1-D data, if:
For 1-D data, if an instrument model is not used, the units are (perhaps incorrectly) assumed to be counts, or counts per bin-width. See the Note on Units below.
For 2-D data, if a region descriptor is given, then the total integrated photon flux within that region is returned; otherwise, the integration is carried out over the entire input image.
Note on Units: in its current incarnation, Sherpa has no explicit knowledge of data or model units. The units displayed with computed fluxes are defaults, generally correct for standard analyses of 1-D PHA energy/wavelength spectra (XSPEC-like analyses). They may be incorrect for non-standard analyses, or for analyses of 2-D spatial images with exposure maps, etc. The correct units can be determined by working backwards from the data, taking into account the exposure time, the units of the instrument model, the bin units, etc.
Tip: To perform background subtraction in Sherpa, the command SUBTRACT must be issued; this is in contrast to XSPEC, which performs background subtraction automatically.
The photon flux may be computed using the Sherpa/S-Lang module functions get_flux (or get_pflux) and get_bflux (or get_bpflux)).
Examples:
Calculate the integrated photon flux over the full energy range:
sherpa> FLUX Flux for source dataset 1: 0.00579108 photons/cm**2/s
Calculate the integrated background photon flux over the range 2 to 10 keV:
sherpa> BPFLUX (2.0:10.0) Flux for background dataset 1: 5.09639e-05 photons/cm**2/s
Calculate the photon flux at a single energy (2.0 keV) for the power-law component of a source expression:
sherpa> SOURCE 1 = XSWABS[A] * POW[P] sherpa> FLUX 1 (2.0) P Flux for source dataset 1: 0.000494404 photons/cm**2/s/keV
Calculate the total photon flux over the energy range 2.0 to 4.0 keV for a model stack:
sherpa> FOO = POW[P] + GAUSS[G] sherpa> SOURCE 1 = XSWABS[A] * FOO sherpa> PFLUX 1 (2:4) FOO Flux for source dataset 1: 0.000498425 photons/cm**2/s
Calculate the total flux within circles of radius 5 and 10 in a 2-D image (note, the quotes are necessary):
sherpa> SOURCE = GAUSS2D[G] sherpa> FLUX 1 "CIRCLE(247,257,5)" Flux for source dataset 1: 1614.79 counts sherpa> FLUX 1 "CIRCLE(247,257,10)" Flux for source dataset 1: 3142.15 counts
Prohibits model parameter(s) from varying.
sherpa> FREEZE <arg_1> [<arg_2> ...]
![]() arg
arg![]() may be:
may be:
| Argument | Description |
|---|---|
| Freezes the specified model component parameter. | |
| Freezes the specified model component parameter. | |
| Freezes all parameters of the specified model component. | |
| Freezes all parameters of the specified model component. | |
| Freezes the parameters of all model components within the
specified model stack (SOURCE, BACKGROUND,
PILEUP, |
|
| Freezes the parameters of all model components within the user-defined model stack. |
The command THAW is used to allow model parameter values to vary.
In addition, model parameters may be frozen using the equivalent command
If model parameter prompting is enabled,
the user may freeze a parameter by
entering ![]()
![]() value
value![]() :
:![]() min
min![]() :
:![]() max
max![]()
![]() ,-1
at the prompt; the -1 sets the parameter to be frozen.
,-1
at the prompt; the -1 sets the parameter to be frozen.
Model parameters may also be frozen using the Sherpa/S-Lang module functions set_frozen and set_par.
Examples:
Freeze a model parameter:
sherpa> PARAMPROMPT OFF sherpa> GAUSS[modelb] sherpa> FREEZE modelb.ampl
The last command freezes the parameter ampl of modelb.
Thaw a model parameter and freeze a model parameter:
sherpa> THAW modelb.3 sherpa> FREEZE modelb.3
The first command thaws the third parameter of modelb. The last command freezes the third parameter of modelb.
Thaw all model parameters and freeze two model parameters:
sherpa> THAW modelb sherpa> FREEZE modelb.fwhm modelb.pos
First, all parameters of modelb are thawed. The last command then freezes the fwhm and pos parameters of modelb.
Freeze or thaw all source component parameters at once:
sherpa> PARAMPROMPT OFF
Model parameter prompting is off
sherpa> POW[modelc]
sherpa> GAUSS[modelf]
sherpa> SOURCE 2 = modelc + modelf
sherpa> FREEZE SOURCE 2
sherpa> SHOW SOURCE 2
Source 2:
(modelc + modelf)
powlaw1d[modelc] (integrate: on)
Param Type Value Min Max Units
----- ---- ----- --- --- -----
1 gamma frozen 1 -10 10
2 ref frozen 1-3.4028e+38 3.4028e+38
3 ampl frozen 1 1e-20 3.4028e+38
gauss1d[modelf] (integrate: on)
Param Type Value Min Max Units
----- ---- ----- --- --- -----
1 fwhm frozen 10 1.1755e-38 3.4028e+38
2 pos frozen 0-3.4028e+38 3.4028e+38
3 ampl frozen 1-3.4028e+38 3.4028e+38
sherpa> THAW SOURCE 2
sherpa> SHOW SOURCE 2
(modelc + modelf)
powlaw1d[modelc] (integrate: on)
Param Type Value Min Max Units
----- ---- ----- --- --- -----
1 gamma thawed 1 -10 10
2 ref frozen 1-3.4028e+38 3.4028e+38
3 ampl thawed 1 1e-20 3.4028e+38
gauss1d[modelf] (integrate: on)
Param Type Value Min Max Units
----- ---- ----- --- --- -----
1 fwhm thawed 10 1.1755e-38 3.4028e+38
2 pos thawed 0-3.4028e+38 3.4028e+38
3 ampl thawed 1-3.4028e+38 3.4028e+38
This example illustrates the use of FREEZE SOURCE and THAW SOURCE to freeze and thaw all source component parameters at once, respectively. Note that thawing of some model parameters (e.g., POWLAW1D.ref) is not permitted.
Freeze a model parameter:
sherpa> modelb.ampl.TYPE = FREEZE
This command freezes the parameter ampl of modelb. The following commands are each equivalent:
sherpa> modelb.3.TYPE = FREEZE sherpa> FREEZE modelb.ampl sherpa> FREEZE modelb.3
Freeze model parameters:
sherpa> ERASE ALL
sherpa> PARAMPROMPT ON
Model parameter prompting is on
sherpa> GAUSS[modelb]
modelb.fwhm parameter value [10] 2,-1
modelb.pos parameter value [0] ,-1
modelb.ampl parameter value [1]
sherpa> SHOW modelb
gauss1d[modelb]
Param Type Value Min Max Units
----- ---- ----- --- --- -----
1 fwhm frozen 2 1.1755e-38 3.4028e+38
2 pos frozen 0-3.4028e+38 3.4028e+38
3 ampl thawed 1-3.4028e+38 3.4028e+38
In this example, parameters are frozen by entering
![]() value
value![]() , -1 at the model parameter value prompt.
Note that , -1 at the model parameter value prompt
accepts the given initial parameter value and freezes that parameter.
, -1 at the model parameter value prompt.
Note that , -1 at the model parameter value prompt
accepts the given initial parameter value and freezes that parameter.
Freeze all model parameters at once; thaw all source parameters at once:
sherpa> PARAMPROMPT OFF
Model parameter prompting is off
sherpa> DATA data/example.pha
sherpa> GAUSS[modelc]
sherpa> SOURCE = modelb + modelc
sherpa> FREEZE modelc
sherpa> SHOW SOURCE
(modelb + modelc)
gauss1d[modelb] (integrate: on)
Param Type Value Min Max Units
----- ---- ----- --- --- -----
1 fwhm frozen 2 1.1755e-38 3.4028e+38
2 pos frozen 0-3.4028e+38 3.4028e+38
3 ampl thawed 1-3.4028e+38 3.4028e+38
gauss1d[modelc] (integrate: on)
Param Type Value Min Max Units
----- ---- ----- --- --- -----
1 fwhm frozen 0.7113 0.0071 71.1283
2 pos frozen 0.9442 0.0276 14.5494
3 ampl frozen 0.0001 1.0564e-06 0.0106
sherpa> THAW SOURCE
sherpa> SHOW SOURCE
(modelb + modelc)
gauss1d[modelb] (integrate: on)
Param Type Value Min Max Units
----- ---- ----- --- --- -----
1 fwhm thawed 2 1.1755e-38 3.4028e+38
2 pos thawed 0-3.4028e+38 3.4028e+38
3 ampl thawed 1-3.4028e+38 3.4028e+38
gauss1d[modelc] (integrate: on)
Param Type Value Min Max Units
----- ---- ----- --- --- -----
1 fwhm thawed 0.7113 0.0071 71.1283
2 pos thawed 0.9442 0.0276 14.5494
3 ampl thawed 0.0001 1.0564e-06 0.0106
Note that the command FREEZE modelc freezes all parameters of the source model component modelc, while THAW SOURCE thaws all parameters of both source model components.
Computes significance using the F test.
sherpa> FTEST <dof_1> <stat_1> <dof_2> <stat_2>
The command arguments are:
| Argument | Description |
|---|---|
| Number of degrees of freedom (dof) for the fit of the null hypothesis (the simple model). | |
| Best-fit statistic for the null hypothesis. | |
| Number of degrees of freedom in the fit of the alternative hypothesis (more complex model). | |
| Best-fit statistic for the alternative hypothesis. |
The ![]() -test is a model comparison test. Model
comparison tests are used to select from two competing models that
which best describes a particular dataset.
-test is a model comparison test. Model
comparison tests are used to select from two competing models that
which best describes a particular dataset.
A model comparison test
statistic ![]() is created from the best-fit
statistics of each fit; as with all statistics, it is sampled from a
probability distribution
is created from the best-fit
statistics of each fit; as with all statistics, it is sampled from a
probability distribution ![]() .
The test significance is defined as the integral of
.
The test significance is defined as the integral of ![]() from the observed value of
from the observed value of ![]() to infinity. The significance quantifies the
probability that one would select the more complex model when in
fact the null hypothesis is correct. A standard threshold for
selecting the more complex model is significance
to infinity. The significance quantifies the
probability that one would select the more complex model when in
fact the null hypothesis is correct. A standard threshold for
selecting the more complex model is significance ![]() 0.05 (the "95%
criterion" of statistics).
0.05 (the "95%
criterion" of statistics).
The ![]() -test may be used if:
-test may be used if:
If these conditions are fulfilled, then the observed
![]() statistic
is sampled from the
statistic
is sampled from the ![]() distribution,
whose shape is a function
of
distribution,
whose shape is a function
of ![]() dof_1
dof_1![]() and
and ![]() dof_2
dof_2![]() .
(The tail integral may be
computed analytically using an incomplete beta function; see any
basic statistics text for details.)
If these conditions
are not fulfilled, then the
.
(The tail integral may be
computed analytically using an incomplete beta function; see any
basic statistics text for details.)
If these conditions
are not fulfilled, then the ![]() -test
significance may not be accurate.
-test
significance may not be accurate.
One can create three ![]() statistics
out of the best-fit statistics for two model fits; the most
powerful
statistics
out of the best-fit statistics for two model fits; the most
powerful ![]() -test, at least for line detection, uses
the change in statistic from one fit to the next as
-test, at least for line detection, uses
the change in statistic from one fit to the next as
![]() stat_1
stat_1![]() , the additional number of parameters in the more
complex model (
, the additional number of parameters in the more
complex model (![]() delta_dof
delta_dof![]() ) for
) for ![]() dof_1
dof_1![]() ,
the best-fit of the more complex model for
,
the best-fit of the more complex model for ![]() stat_2
stat_2![]() ,
and the number of degrees of freedom for the more complex model for
,
and the number of degrees of freedom for the more complex model for
![]() dof_2
dof_2![]() .
.
The ![]() -test significance can also be retrieved
using the Sherpa/S-Lang module function
get_ftest.
-test significance can also be retrieved
using the Sherpa/S-Lang module function
get_ftest.
Examples:
Compute the ![]() -test significance given two fits:
-test significance given two fits:
sherpa> FTEST 2 20.28 34 33.63 significance = 0.000328079
As noted above,
for line fits, the first two numbers should be the difference in
degrees of freedom and fit statistic, respectively, between the null
hypothesis (continuum) fit (for which
![]() 53.91 for 36 dof),
and the alternative hypothesis (continuum-plus-line) fit (for which
53.91 for 36 dof),
and the alternative hypothesis (continuum-plus-line) fit (for which
![]() 33.63 for 34 dof).
In general, if the significance is smaller
than a predefined threshold (e.g., 0.05), then the more
complex model is selected (as it is in this case). Otherwise the null
hypothesis is selected.
33.63 for 34 dof).
In general, if the significance is smaller
than a predefined threshold (e.g., 0.05), then the more
complex model is selected (as it is in this case). Otherwise the null
hypothesis is selected.
Assigns x-axis values taken from a plot to model parameters.
sherpa> GETX [<arg>] <modelname>.{<paramname> | <#>} \
[<modelname>.{<paramname> | <#>} ...]
where ![]() modelname
modelname![]() is the name that has been given
to a model component by the user.
is the name that has been given
to a model component by the user.
Notice that either ![]() paramname
paramname![]() or
or ![]() #
#![]() may be used to specify the parameter to which the value will be assigned.
When the value to be assigned
is the non-negative value of the difference between two x-axis
values,
may be used to specify the parameter to which the value will be assigned.
When the value to be assigned
is the non-negative value of the difference between two x-axis
values, ![]() is 2.
is 2.
To take an x-axis value from a plot, and assign it to a model parameter:
To take two x-axis values from a plot, and assign the non-negative value of their difference to a model parameter:
See the CREATE command for further information and examples of alternative methods for setting model parameter values individually.
One may quit GETX by typing q. The previously assigned parameter value will be restored. Note, however, that if multiple parameter values are being set, only the one being altered when q is typed will have its value restored.
Examples:
Set a model parameter value to an x-axis value taken from a plot:
sherpa> DATA example.dat sherpa> PARAMPROMPT OFF Model parameter prompting is off sherpa> GAUSS[modelb] sherpa> LPLOT DATA sherpa> GETX modelb.pos <left-mouse-click once at the desired x-axis value> sherpa> SHOW modelb
The command GAUSS![]() modelb
modelb![]() assigns the name modelb to the Sherpa
model component GAUSS.
Next, the 1-D data are plotted.
The command GETX modelb.pos readies the cursor for selecting
the desired x-axis value from the plot, for parameter pos of modelb.
The user should then left-mouse-click (or hit the character e) at
the desired x-axis location.
The command SHOW modelb will show the current
parameter values and their ranges, for component modelb.
assigns the name modelb to the Sherpa
model component GAUSS.
Next, the 1-D data are plotted.
The command GETX modelb.pos readies the cursor for selecting
the desired x-axis value from the plot, for parameter pos of modelb.
The user should then left-mouse-click (or hit the character e) at
the desired x-axis location.
The command SHOW modelb will show the current
parameter values and their ranges, for component modelb.
Set a model parameter value to the non-negative difference between two x-axis values taken from a plot:
sherpa> GETX 2 modelb.fwhm <left-mouse-click once at the desired first x-axis value> <and then left-mouse-click again at the desired second x-axis value> sherpa> SHOW modelb
Here, the command GETX 2 modelb.fwhm readies the cursor for selecting the two desired x-axis values from the plot. The non-negative difference between these two values will be assigned to parameter fwhm of modelb. The command SHOW modelb will show the current parameter values and their ranges, for modelb.
Assigns y-axis values taken from a plot to model parameters.
sherpa> GETY [<arg>] <modelname>.{<paramname> | <#>} \
[<modelname>.{<paramname> | <#>} ...]
where ![]() modelname
modelname![]() is the name that has been given
to a model component by the user.
is the name that has been given
to a model component by the user.
Notice that either ![]() paramname
paramname![]() or
or ![]() #
#![]() may be used to specify the parameter to which the value will be assigned.
When the value to be assigned
is the non-negative value of the difference between two y-axis
values,
may be used to specify the parameter to which the value will be assigned.
When the value to be assigned
is the non-negative value of the difference between two y-axis
values, ![]() is 2.
is 2.
To take a y-axis value from a plot, and assign it to a model parameter:
To take two y-axis values from a plot, and assign the non-negative value of their difference to a model parameter:
See the CREATE command for further information and examples of alternative methods for setting model parameter values individually.
One may quit GETY by typing q. The previously assigned parameter value will be restored. Note, however, that if multiple parameter values are being set, only the one being altered when q is typed will have its value restored.
Examples:
Set a model parameter value to a y-axis value taken from a plot:
sherpa> DATA example.dat sherpa> PARAMPROMPT OFF Model parameter prompting is off sherpa> GAUSS[modelb] sherpa> LPLOT DATA sherpa> GETY modelb.ampl <left-mouse-click once at the desired y-axis value> sherpa> SHOW modelb
The command GAUSS![]() modelb
modelb![]() assigns the name modelb to the Sherpa model component GAUSS.
Next, the 1-D data are plotted.
The command GETY modelb.ampl readies the cursor for selecting
the desired y-axis value from the plot, for parameter ampl of modelb.
The user should then left-mouse-click (or hit the character e) at
the desired y-axis location.
The command SHOW modelb will show the current
parameter values and their ranges, for component modelb.
assigns the name modelb to the Sherpa model component GAUSS.
Next, the 1-D data are plotted.
The command GETY modelb.ampl readies the cursor for selecting
the desired y-axis value from the plot, for parameter ampl of modelb.
The user should then left-mouse-click (or hit the character e) at
the desired y-axis location.
The command SHOW modelb will show the current
parameter values and their ranges, for component modelb.
Set a model parameter value to the non-negative difference between two y-axis values taken from a plot:
sherpa> GETY 2 modelb.ampl <left-mouse-click once at the desired first y-axis value> <and then left-mouse-click again at the desired second y-axis value> sherpa> SHOW modelb
Here, the command GETY 2 modelb.amply readies the cursor for selecting the two desired y-axis values from the plot. The non-negative difference between these two values will be assigned to parameter ampl of modelb. The command SHOW modelb will show the current parameter values and their ranges, for modelb.
Reports information on the goodness-of-fit.
sherpa> GOODNESS [<dataset range> | ALLSETS]
![]() dataset range
dataset range![]()
![]() # (or more generally #:#,#:#, etc.) such that
# specifies a dataset number and #:# represents an inclusive range of datasets;
one may specify multiple inclusive ranges by separating them with
commas. The default is to obtain information from all appropriate datasets.
# (or more generally #:#,#:#, etc.) such that
# specifies a dataset number and #:# represents an inclusive range of datasets;
one may specify multiple inclusive ranges by separating them with
commas. The default is to obtain information from all appropriate datasets.
GOODNESS reports to the user information about how well specified models fit to the data. At a minimum, it reports: the choice of statistic; the number of bins in the fit; the number of degrees of freedom (dof), i.e., the number of bins minus the number of free parameters; and the statistic value. (See the documentation on the command STATISTIC for more information on how to set the current statistic within Sherpa.)
If the chosen statistic is one of the
![]() statistics, or the
CSTAT statistic, then more information is
shown: the reduced statistic, i.e., the statistic value
divided by the number of dof; and the probability, or
statistics, or the
CSTAT statistic, then more information is
shown: the reduced statistic, i.e., the statistic value
divided by the number of dof; and the probability, or
![]() -value:
-value:
 |
(1.3) |
where
![]() represents a
specific observed value of
represents a
specific observed value of ![]() (e.g., resulting from a fit),
(e.g., resulting from a fit),
![]() is the number of degrees of freedom
(number of bins minus number of free parameters), and
is the number of degrees of freedom
(number of bins minus number of free parameters), and
![]() is the
is the ![]() probability
sampling distribution.
probability
sampling distribution.
![]() measures the probability that one would observe
the value
measures the probability that one would observe
the value
![]() , or a larger value,
if the assumed model is true
and the best-fit model parameters are the true parameter values.
A value that is too small
(e.g.,
, or a larger value,
if the assumed model is true
and the best-fit model parameters are the true parameter values.
A value that is too small
(e.g., ![]()
![]() 0.05)
indicates that the selected
model does not accurately portray the data, while a value that is too
large (
0.05)
indicates that the selected
model does not accurately portray the data, while a value that is too
large (![]() -
-![]() 1) indicates that the fit is
"too good."
The usual cause of a fit that is too good is an overestimation of the
errors (e.g., by using
CHI GEHRELS in the low-counts regime
(see note below), or
by adding in too much systematic error). Increasing
the errors decreases
1) indicates that the fit is
"too good."
The usual cause of a fit that is too good is an overestimation of the
errors (e.g., by using
CHI GEHRELS in the low-counts regime
(see note below), or
by adding in too much systematic error). Increasing
the errors decreases
![]() ,
and increases
,
and increases ![]() .
.
Note that the accuracy of ![]() is dependent
upon whether the selected statistic
is actually sampled from the
is dependent
upon whether the selected statistic
is actually sampled from the ![]() distribution!
This may not be the case if the number of counts in any bin is too small
(
distribution!
This may not be the case if the number of counts in any bin is too small
(![]() 5-10).
5-10).
The information output by GOODNESS may be retrieved using the Sherpa/S-Lang module function get_goodness.
Examples:
Report information on the goodness-of-fit:
sherpa> GOODNESS Goodness: computed with Chi-Squared Data Variance DataSet 1: 100 data points -- 99 degrees of freedom. Statistic value = 82.7136 Probability [Q-value] = 0.880939 Reduced statistic = 0.835491
Causes Sherpa to apply a read-in bin grouping scheme to source or background data.
sherpa> [B]GROUP [# [ID]]
GROUP is used to group source data, while BGROUP is used to group background data.
# specifies the number of the dataset to which the grouping scheme is to be applied (default dataset number is 1). The ID modifier is used if and only if the Sherpa state object variable multiback is set to 1, i.e., if more than one background dataset is to be associated with a single source dataset. The ID modifier may be any unreserved string (e.g., A, foo, etc.), i.e., a string that is not a parsable command.
The commands GROUP and UNGROUP allow a user to toggle back and forth between the analysis of grouped and ungrouped data, after grouping assignments have been read into Sherpa via the command READ GROUPS. (In a future version of Sherpa, the GROUP may be issued automatically upon the reading in of groups.)
Note the issuing the GROUP causes Sherpa to delete any defined filters for the specified dataset.
Also note that even if the data are grouped, the user may continue to read in filters, weights, etc., whose values map to the ungrouped data; Sherpa will do the grouping automatically:
The user may also read in filters, weights, etc., whose values map to the grouped data; these values are used directly.
NOTE: in CIAO 3.0, the commands GROUP and UNGROUP may not be used with PHA data that has a GROUPING column. This is because these data are grouped before Sherpa ever has control of them, and Sherpa thus has no knowledge of how the ungrouped data are distributed among bins. This will be changed in a future version of Sherpa.
Examples:
Input data from an ASCII file; input a grouping scheme; group and ungroup the data:
sherpa> ERASE ALL
sherpa> $more spec_short.dat
1 59.0000 0 1 1 .05 0
2 46.0000 0 1 1 .05 0
3 49.0000 0 1 1 .05 5
4 65.0000 0 -1 1 .05 0
5 60.0000 2 -1 1 .05 0
6 60.0000 2 1 .1 .05 0
7 74.0000 2 -1 .1 .05 0
8 58.0000 2 -1 .1 .05 0
9 55.0000 2 1 .1 .05 0
10 70.0000 1 -1 .1 .05 5
11 61.0000 1 -1 .1 .05 0
12 75.0000 1 1 1 .05 0
13 56.0000 1 -1 1 .05 0
14 60.0000 1 -1 1 .05 0
15 45.0000 1 1 1 .05 0
16 63.0000 1 -1 1 .05 5
17 63.0000 1 -1 1 .05 0
18 56.0000 0 1 1 .05 0
19 58.0000 0 -1 1 .05 0
20 54.0000 0 -1 1 .05 0
sherpa> DATA spec_short.dat
sherpa> READ GROUPS spec_short.dat 1 4
sherpa> GROUP
WARNING: any applied filters are being deleted!
sherpa> WRITE DATA
Write X-Axis: Bin Y-Axis: Flux (Counts)
1 59
2 46
3 174
6 192
9 186
12 191
15 171
18 168
sherpa> UNGROUP
WARNING: any applied filters are being deleted!
Estimates initial parameter values and ranges, based on input data.
sherpa> GUESS <arg> [# [ID]]
# specifies the dataset whose data are to be used to help estimated parameter values. The ID modifier is used only for guesses involving background data, and then if and only if the Sherpa state object variable multiback is set to 1, i.e., if more than one background dataset is to be associated with a single source dataset. The ID modifier may be any unreserved string (e.g., A, foo, etc.), i.e., a string that is not a parsable command.
![]() arg
arg![]() may be:
may be:
| Argument | To perform an estimate for: |
|---|---|
| MODELS | All current model components. |
| All current model components in the named stack
(SOURCE, BACKGROUND,
PILEUP, |
|
| The specified model component. | |
| The specified model component. |
In addition, ![]() arg
arg![]() may be either ON
or OFF, to turn Sherpa's parameter-value-guessing
mechanism on and off respectively.
may be either ON
or OFF, to turn Sherpa's parameter-value-guessing
mechanism on and off respectively.
Note that:
sherpa> GAUSS[g]
then parameter estimates will be made using the first dataset. To refine the estimates for, e.g., dataset 3, do the following:
sherpa> SOURCE 3 = g sherpa> GUESS SOURCE 3
sherpa> SOURCE 4 = GAUSS[g]
then parameter estimates will be made using the numbered dataset, in this example, dataset number 4.
sherpa> RSP[a](example2.arf,example2.rmf) sherpa> SOURCE = GAUSS[g]
then parameter estimates will be made using the counts data (divided by the observation time, if provided in the PHA header); i.e., they will not take into account the area information provided in the ARF. For good parameter estimates, always set the instrument!
sherpa> RSP[a](example2.arf,example2.rmf) sherpa> INSTRUMENT = a sherpa> SOURCE = GAUSS[g]
See the CREATE command for more information and other examples.
Examples:
Estimate initial parameter values and ranges, based on input dataset number 1:
sherpa> PARAMPROMPT OFF sherpa> POLY[modela] sherpa> DATA example1.dat sherpa> GUESS modela
This command estimates parameter values and ranges for component modela, based on dataset 1.
Estimate initial parameter values and ranges, based on a specified input dataset:
sherpa> DATA 2 example2.dat sherpa> GUESS MODELS 2
This command estimates parameter values and ranges for all current model components, based on dataset 2.
Estimate initial parameter values and ranges for source models and their corresponding datasets, when multiple source models have been defined and multiple datasets have been input:
sherpa> ERASE ALL sherpa> READ DATA 1 example1.dat sherpa> READ DATA 2 example2.dat sherpa> READ DATA 3 example3.dat sherpa> POW[modelc] sherpa> GAUSS[modelf] sherpa> BBODY[modelh] sherpa> SOURCE 1 = modelc sherpa> SOURCE 2 = modelf sherpa> SOURCE 3 = modelh sherpa> GUESS SOURCE 1
This command estimates initial parameter values and ranges,
based on dataset number 1,
for the components of the source model for dataset number 1
(i.e., modelc).
Note, however, that these estimates
were already made automatically when component modelc was
first established with the command POW![]() modelc
modelc![]() .
.
sherpa> GUESS SOURCE 2
Estimates initial parameter values and ranges, based on dataset number 2, for the components of the source model for dataset number 2 (i.e., modelf). Note that until this command is issued, the initial parameter values for modelf are estimates based on dataset number 1.
sherpa> GUESS SOURCE 3
Estimates initial parameter values and ranges, based on dataset number 3, for the components of the source model for dataset number 3 (i.e., modelh). Note that until this command is issued, the initial parameter values for modelh are estimates based on dataset number 1.
Specifies a data portion to be excluded, for 1- or 2-D data.
sherpa> IGNORE [{SOURCE | BACK}] [<dataset range> | ALLSETS] [ID] <arg>
where ![]() dataset range
dataset range![]()
![]() #, or more generally #:#,#:#,...,
such that
# specifies a dataset number, and #:# represents an inclusive range of datasets;
one may specify multiple inclusive ranges by separating them
with commas. The default dataset is dataset 1.
#, or more generally #:#,#:#,...,
such that
# specifies a dataset number, and #:# represents an inclusive range of datasets;
one may specify multiple inclusive ranges by separating them
with commas. The default dataset is dataset 1.
The modifiers SOURCE and BACK may be used to specify that the filter is to be applied to either the source or background data only. If neither is specified, then the filter is applied to both the source and background datasets. Note that in CIAO 3.1 when omitting the modifiers the definition of INSTRUMENT BACK is required for filtering PHA data in energy/wave if either background file or background models have been defined.
The ID modifier is used only for the command IGNORE BACK (see below), and even then if and only if the Sherpa state object variable multiback is set to 1, i.e., if more than one background dataset is to be associated with a single source dataset. The ID modifier may be any unreserved string (e.g., A, foo, etc.), i.e., a string that is not a parsable command.
![]() arg
arg![]() is either:
is either:
| Argument | To exclude: |
|---|---|
| ALL | The entire dataset. |
| BAD | All PHA channels with quality flags $ |
| FILTER |
Bins with x-values satisfying |
| {BINS |
Bins whose sequential numbers satisfy |
| ENERGY |
Bins with x-values in energy space satisfying |
| WAVE |
Bins with x-values in wavelength space satisfying |
| PLOT | A range selected interactively from an open plot (1-D only). |
| IMAGE | A region selected interactively from an open image (2-D only). |
| {IMAGE |
Pixels with logical coordinates satisfying |
| PHYSICAL |
Pixels with physical coordinates satisfying |
| {WCS |
Pixels with world coordinates satisfying |
The typical ![]() filterExpr
filterExpr![]() for 1-D data is the
range filter:
for 1-D data is the
range filter:
| This Filter Expression: | Means: |
|---|---|
| #:# | Exclude all data from the first value to the second value, inclusive. |
| #: | Exclude all data above the given value, inclusive. |
| :# | Exclude all data below the given value, inclusive. |
| # | Exclude the data point corresponding to the given value. |
For 2-D data, ![]() filterExpr
filterExpr![]() is a quote-delimited region
specification. See "ahelp dmregions" for more information on
allowed region specifications.
is a quote-delimited region
specification. See "ahelp dmregions" for more information on
allowed region specifications.
For more information on filter expressions, see the
Sherpa Filtering
Chapter for the full
![]() filterExpr
filterExpr![]() definition, as well as information
regarding other filtering methods.
definition, as well as information
regarding other filtering methods.
The difference between the arguments FILTER and
{BINS ![]() CHANNELS} may be
illustrated with the following simplistic ASCII dataset:
CHANNELS} may be
illustrated with the following simplistic ASCII dataset:
x y - - 22.6 10 22.7 9 22.8 12 22.9 7
The command IGNORE FILTER 22.65:22.85 will cause the middle two bins to be filtered out. This is equivalent to IGNORE BINS 2:3, i.e., ignore the 2nd and 3rd bins. For PHA datasets, IGNORE FILTER and IGNORE BINS will lead to the same result, since the x-values of the PHA channels are sequential integers: 1, 2, 3...
To use the commands IGNORE ENERGY or IGNORE WAVE, a PHA dataset must have been read in, and an INSTRUMENT model stack defined. Note that regardless of the current ANALYSIS setting, one may filter using either IGNORE ENERGY or IGNORE WAVE. See the examples below.
To specify regions to ignore within an image:
Verify results using IMAGE FILTER.
To specify regions to ignore within a plot:
Ranges/regions to be ignored may be alternatively set using the Sherpa/S-Lang module functions set_ignore, set_ignore_bad, and set_ignore2d, et al.
Examples:
Exclude all data values:
sherpa> DATA example.dat sherpa> IGNORE ALL
The last command tells Sherpa to ignore all data in dataset 1.
Exclude a particular data range from the source, background, or both:
sherpa> DATA data/data.dat sherpa> BACK data/data_bckg.dat sherpa> IGNORE SOURCE FILTER 5:10 sherpa> LPLOT 2 DATA BACK
After the input of source and background data, the command IGNORE SOURCE FILTER 5:10 tells Sherpa to exclude those bins in the source dataset whose x-axis values are equal to 5 through 10, inclusive. See the Sherpa Filtering Chapter for further examples of filter expressions and usage of the IGNORE command. With the final command, a plot of both the source and background data illustrates that the filter was applied to the source data only; the background data remains unfiltered.
sherpa> NOTICE ALL sherpa> IGNORE BACK FILTER 5:10 sherpa> LPLOT 2 DATA BACK sherpa> LPLOT BFILTER
The NOTICE ALL command eliminates any filters applied to the source and background datasets. The command IGNORE BACK FILTER 5:10 tells Sherpa to exclude those bins in the background dataset whose x-axis values are equal to 5 through 10, inclusive. With the first LPLOT command, a plot of both the source and background data illustrates that the filter was applied to the background data only; the source data remains unfiltered. The final command plots the filter status of each background data point.
sherpa> NOTICE ALL sherpa> IGNORE FILTER 5:10 sherpa> LPLOT 2 DATA BACK sherpa> LPLOT FILTER
The NOTICE ALL command eliminates any filters applied to the source and background datasets. The command IGNORE FILTER 5:10 tells Sherpa to exclude those bins in both the source and background datasets whose x-axis values are equal to 5 through 10, inclusive. With the first LPLOT command, a plot of both the source and background data illustrates that the filter was applied to both datasets. The final command plots the filter status of each source data point.
Exclude a 2-D region, specified from an image display:
sherpa> READ DATA example_img.fits sherpa> IMAGE DATA sherpa> NOTICE ALL <mark include region(s)> sherpa> IGNORE IMAGE sherpa> IMAGE FILTER
In this example, 2-D image data is first displayed. Then the data filter is set to include the entire image, with the command NOTICE ALL. (This command is not needed in this particular example but is shown for completeness.) Next, the user chooses regions, by placing include markers on the displayed image. The command IGNORE IMAGE sets the data filter to exclude data within the marked regions. The command IMAGE FILTER displays the resulting filter.
Exclude a 1-D data range, specified from a plot display:
sherpa> READ DATA example.dat sherpa> LPLOT DATA sherpa> NOTICE ALL sherpa> IGNORE PLOT <left-mouse-click once at the desired minimum x-axis value> <and then left-mouse-click again at the desired maximum x-axis value> sherpa> LPLOT FILTER sherpa> LPLOT DATA
In this example, 1-D data is first displayed. Then the data filter is set to include the entire dataset, with the command NOTICE ALL. (This command is not needed in this particular example but is shown for completeness.) The command IGNORE PLOT readies the cursor for selecting the desired filter region, and the user should then left-mouse-click first at the desired minimum x-axis location and then again at the maximum x-axis location. After the second left-mouse-click, the Sherpa command prompt is returned. The command LPLOT FILTER will then plot the data region that you have marked for exclusion. Finally, the dataset is plotted again, with the command LPLOT DATA, showing that the selected regions have been properly excluded.
Exclude a 1-D data range, specified from a plot display, for dataset number 2:
sherpa> READ DATA 1 example1.dat sherpa> READ DATA 2 example2.dat sherpa> LPLOT DATA 2 sherpa> NOTICE 2 ALL sherpa> IGNORE 2 PLOT <left-mouse-click once at the desired minimum x-axis value> <and then left-mouse-click again at the desired maximum x-axis value> sherpa> LPLOT FILTER 2 sherpa> LPLOT DATA 2 sherpa> sherpa> NOTICE ALL sherpa> IGNORE PLOT <left-mouse-click once at the desired minimum x-axis value> <and then left-mouse-click again at the desired maximum x-axis value> sherpa> LPLOT FILTER sherpa> LPLOT DATA
In this example, two 1-D datasets are input, and dataset number 2 is first displayed. Then, the data filter is set to include all of dataset number 2, with the command NOTICE 2 ALL. (This command is not needed in this particular example but is shown for completeness.) The command IGNORE 2 PLOT readies the cursor for selecting the desired filter region for dataset number 2, and the user should then left-mouse-click first at the desired minimum x-axis location and then again at the maximum x-axis location. After the second left-mouse-click, the Sherpa command prompt is returned. The command LPLOT FILTER 2 will then plot the data region that you have marked for exclusion from dataset number 2. Finally, dataset number 2 is plotted again, with the command LPLOT DATA 2, showing that the selected regions have been properly excluded.
Next, the user sets the data filter to include all of dataset number 1, with the command NOTICE ALL. (This command is not needed in this particular example but is shown for completeness.) The command IGNORE PLOT readies the cursor for selecting the desired filter region for dataset number 1, and the user should then left-mouse-click first at the desired minimum x-axis location and then at the maximum x-axis location (from the plot that's currently displayed of dataset number 2). The command LPLOT FILTER will then plot the data region that you have marked for exclusion from dataset number 1. Finally, dataset number 1 is plotted again, with the command LPLOT ALL, showing that the selected regions have been properly excluded. Note that dataset number 1 was interactively filtered, from a display of dataset number 2.
Exclude particular data values and ranges:
sherpa> DATA 3 example.dat sherpa> NOTICE 3 ALL sherpa> IGNORE 3 FILTER 4, 8:, 1:3
The first command, NOTICE 3 ALL, sets all of dataset number 3 to be included, and so clears any previous filters. (This command is not needed in this particular example but is shown for completeness.) The second command uses a filter expression to exclude those x-axis data values that are equal to 4, greater-than or equal to 8, or equal to 1 through 3, inclusive. See the Sherpa Filtering Chapter for further examples of filter expressions and usage of the IGNORE command.
Exclude PHA channels with quality flags different than 0:
sherpa> DATA data/example.pha sherpa> IGNORE BAD
Filter PHA data by energy, or wavelength:
sherpa> ERASE ALL sherpa> DATA data/example2.pha The inferred file type is PHA. If this is not what you want, please specify the type explicitly in the data command. WARNING: using systematic errors specified in the PHA file. RMF is being input from: <directory_path>/example2.rmf ARF is being input from: <directory_path>/example2.arf Background data are being input from: <directory_path>/example2_bkg.pha sherpa> ANALYSIS ENERGY sherpa> NOTICE ALL sherpa> IGNORE ENERGY 5:10 sherpa> LPLOT DATA sherpa> NOTICE ALL sherpa> IGNORE WAVE 0:20 sherpa> ANALYSIS WAVE sherpa> LPLOT DATA
In this example, the dataset is filtered using IGNORE WAVE even though the ANALYSIS setting is ENERGY. This is possible because header information in the data file allowed for an instrument model to be automatically defined when the data were initially read.
Exclude a 2-D region specified from the command line, in physical coordinates:
sherpa> DATA data/example_img2.fits sherpa> IGNORE PHYSICAL "CIRCLE(4010,3928,100)" sherpa> IMAGE FILTER
To filter in physical coordinates requires no action on the part of the user beyond specifying the PHYSICAL modifier; Sherpa automatically performs the image-to-physical coordinate conversion (if it can). Note that the quote marks are required in CIAO 3.0 when specifying 2-D filter regions. (They are not required when specifying 1-D regions, as seen in the other examples above.) The command IMAGE FILTER displays the resulting filter.
Causes the specified 2-D data to be displayed, via ds9.
sherpa> IMAGE <arg> [# [ID]]
# specifies the number of the dataset (default dataset number is 1). The ID modifier is used for displaying background datasets, and then if and only if the Sherpa state object variable multiback is set to 1, i.e., if more than one background dataset is to be associated with a single source dataset. The ID modifier may be any unreserved string (e.g., A, foo, etc.), i.e., a string that is not a parsable command.
The argument ![]() arg
arg![]() may be any of the following:
may be any of the following:
| Argument | Displays |
|---|---|
| {{DATA |
The source |
| {ERRORS |
The estimated total errors for the source |
| {SYSERRORS |
The assigned systematic errors for the source |
| {STATERRORS |
The estimated statistical errors for the source |
| {{MODEL |
The (convolved) source |
| {FIT |
The data, model, and absolute residuals for source |
| {DELCHI |
The sigma residuals of the source |
| {RESIDUALS |
The absolute residuals of the source |
| {RATIO |
The ratio (data/model) for source |
| {CHI SQU |
The contributions to the |
| {STATISTIC |
The contributions to the current statistic
from each source |
| {WEIGHT |
The statistic weight value assigned to each source |
| {FILTER |
The mask value (0 |
| The (unconvolved) model amplitudes for the
specified model stack (SOURCE,
{BACKGROUND |
|
| The (unconvolved) model amplitudes for the specified user-defined model stack | |
| The (unconvolved) amplitudes of the specified model component (e.g., GAUSS2D) | |
| The (unconvolved) amplitudes of the specified model component (e.g., g) | |
| {EXPMAP |
The unfiltered source |
| {PSF |
The unfiltered source |
If there is no open image window when an IMAGE command is given, one will be created automatically.
In CIAO 3.0, if one displays an image after filtering, what is displayed is
the ![]() data to image
data to image![]() * filter", shown over the range of
the unfiltered dataset. In a future version of Sherpa,
include/exclude regions may also be
superimposed upon the image.
* filter", shown over the range of
the unfiltered dataset. In a future version of Sherpa,
include/exclude regions may also be
superimposed upon the image.
Also note that in CIAO 3.0, images are automatically resized to fit entirely within the image frame. The user may of course subsequently zoom in and/or out.
Related commands include IGNORE IMAGE and NOTICE IMAGE, which are used to interactively define filter regions from an image display.
See the display chapter for more information regarding data display capabilities, including modifying various image characteristics.
sherpa> data "image.fits[opt mem=1000]"
the following DOES NOT work:
sherpa> image "model[opt mem=1000]"
This is because "model" is a token that the Sherpa parser
interprets, and it will treat the rest of the string ("![]() opt
mem
opt
mem![]() 1000
1000![]() ") as an error. A workaround is to write out the file with
the "write" command:
") as an error. A workaround is to write out the file with
the "write" command:
sherpa> write model "out.fits[opt mem=1000]"
Then display out.fits in ds9.
Examples:
Display 2-D data:
sherpa> DATA example_img.fits sherpa> IMAGE DATA
The last command displays dataset number 1. Dataset number 1 must be a 2-D dataset.
Exclude a 2-D region; display the filtered region:
sherpa> IGNORE FILTER "BOX(250,250,50,50)" sherpa> IMAGE FILTER
The first command, IGNORE FILTER "BOX(250,250,50,50)" defines a filter for dataset number 1. The second command displays the defined filter region.
Display 2-D absolute residuals:
sherpa> PARAMPROMPT OFF sherpa> SOURCE = GAUSS2D[g] sherpa> FIT sherpa> IMAGE RESIDUALS
Defines an expression to be used for modeling the instrument in source or background data analysis. The command RESPONSE is equivalent.
sherpa> {INSTRUMENT | RESPONSE} [{SOURCE | BACK}] [# [ID]] = <modelExpr>
where # may specify the number of the dataset (default dataset number is 1). The modifiers SOURCE and BACK may be used to specify the application of the instrument model stack to either the source or background data only. If neither is specified, then the model is used for both the source and background data. The ID modifier is used only for the command INSTRUMENT BACK (see below), and even then if and only if the Sherpa state object variable multiback is set to 1, i.e., if more than one background dataset is to be associated with a single source dataset. The ID modifier may be any unreserved string (e.g., A, foo, etc.), i.e., a string that is not a parsable command.
The model expression,
![]() modelExpr
modelExpr![]() ,
is an algebraic combination of one or more of the following elements:
,
is an algebraic combination of one or more of the following elements:
{<sherpa_modelname> | <sherpa_modelname>[modelname] |
<modelname> }
along with numerical values. The following operators are recognized:
![]() * ( ); however, the operators
* ( ); however, the operators ![]() and * do not have the same meaning
that they do when combining source model components. See below for
details. (See the CREATE command for
more information on establishing model components.)
and * do not have the same meaning
that they do when combining source model components. See below for
details. (See the CREATE command for
more information on establishing model components.)
Note that:
To reset an instrument model stack, issue the command:
sherpa> {INSTRUMENT | RESPONSE} [<dataset range> | ALLSETS] =
Instrument models describe instrument characteristics, such as effective area, a detector's energy response, or a mirror's point-spread function. They are convolved with, e.g., a source model to compute the number of detected counts in each detector bin.
Instrument model stacks are thus fundamentally different from other model
stacks in that the models they contain are not evaluated themselves, but are
used to tranform (i.e., fold) amplitude arrays
(
![]() , instead of
, instead of
![]() ).
(In Sherpa, there are two types of transformations:
multiplication by an array, and multiplication by a redistribution matrix.)
Thus, as noted above, the
instrument stack operators
).
(In Sherpa, there are two types of transformations:
multiplication by an array, and multiplication by a redistribution matrix.)
Thus, as noted above, the
instrument stack operators ![]() and * do not have the same meaning as their
model stack counterparts.
and * do not have the same meaning as their
model stack counterparts.
Instrument models bound by the * operator collectively take a photon
spectrum ![]() and fold it to a counts spectrum
and fold it to a counts spectrum
![]() . The order of the models does not matter so long
as only there is only one redistibutive model (e.g., RMF or PSF)
in the set.
. The order of the models does not matter so long
as only there is only one redistibutive model (e.g., RMF or PSF)
in the set.
sherpa> farf1d[a](arf.fits) sherpa> frmf1d[r](rmf.fits) sherpa> instrument = a*r
Here, the photon spectrum ![]() is multiplied by the ARF,
then folded through the RMF. This instrument stack is equivalent to
is multiplied by the ARF,
then folded through the RMF. This instrument stack is equivalent to
sherpa> instrument = rsp[a](rmf.fits,arf.fits)
Sets of instrument models separated by the ![]() operator each fold the same
evaluated photon spectrum
operator each fold the same
evaluated photon spectrum ![]() , with the resulting group
of counts spectra being summed.
, with the resulting group
of counts spectra being summed.
sherpa> farf1d[a1](arf_order1.fits) sherpa> farf1d[a2](arf_order2.fits) sherpa> frmf1d[r1](rmf_order1.fits) sherpa> frmf1d[r2](rmf_order2.fits) sherpa> instrument = a1*r1 + a2*r2
Here, the photon spectrum ![]() is folded through the
combination a1*r1
to produce counts spectrum
is folded through the
combination a1*r1
to produce counts spectrum ![]() ;
;
![]() is also folded through
the combination
a2*r2 to produce counts spectrum
is also folded through
the combination
a2*r2 to produce counts spectrum
![]() .
The overall counts
spectrum is then
.
The overall counts
spectrum is then
![]() .
.
The two rules governing instrument stacks are:
Note that if one wants to do more complex operations (e.g., dividing one arf by another as part of the folding process), one can use S-Lang to do the preliminary dirty work (for this example, the array division; the new array can then be loaded into Sherpa as the "arf" via Sherpa/S-Lang module function load_arf).
For Sherpa version 3.0.2, support for "dummy" instruments and datasets has been added:
One may always overwrite the dummy instruments if they are not appropriate.
Also for Sherpa version 3.0.2, checks have been added that may lead to the instrument stack being deleted if a subsequent DATA or DATASPACE command is issued, if it appears that the models in the stack are incompatible with the input data. In future versions of Sherpa, the instrument stack may be deleted automatically in such situations to avoid analysis problems (i.e., one will always have to specify instrument stacks after inputting data).
Also note that there are several instrument-model-stack-related Sherpa/S-Lang module functions.
Examples:
Define an instrument model using specified input response files:
sherpa> INSTRUMENT 1 = RSP[instrumentA] instrumentA.rmf parameter value [] example.rmf instrumentA.arf parameter value [] example.arf The inferred file type is ARF. If this is not what you want, please specify the type explicitly in the data command.
Define an instrument model, inputting the response files individually:
sherpa> ERASE ALL sherpa> PARAMPROMPT OFF Model parameter prompting is off sherpa> INSTRUMENT 1 = FARF[iarf]*FRMF[irmf] sherpa> iarf.arf = example.arf The inferred file type is ARF. If this is not what you want, please specify the type explicitly in the data command. sherpa> irmf.rmf = example.rmf
Define an instrument model using specified input response files:
sherpa> ERASE ALL sherpa> RSP[instrumentA](example.rmf, example.arf) The inferred file type is ARF. If this is not what you want, please specify the type explicitly in the data command. sherpa> INSTRUMENT 1 = instrumentA
Define an instrument model using specified input response files, including an encircled-energy arf (EEARF):
sherpa> ERASE ALL sherpa> FARF1D[ieearf](example.eearf) The inferred file type is ARF. If this is not what you want, please specify the type explicitly in the data command. sherpa> RSP[instrumentA](example.rmf, example.arf) The inferred file type is ARF. If this is not what you want, please specify the type explicitly in the data command. sherpa> INSTRUMENT 1 = ieearf*instrumentA
Define an instrument model using specified input response files, with a path:
sherpa> ERASE ALL
sherpa> INSTRUMENT 1 = RSP[instrumentA]("data/example.rmf",
"data/example.arf")
The inferred file type is ARF. If this is not what you want, please
specify the type explicitly in the data command.
In all of the above examples, since neither a SOURCE or BACK argument is specified, the same instrument model is established for both the source and background.
Define different source and background instrument models using specified input response files (RMF and ARF only):
sherpa> ERASE ALL sherpa> PARAMPROMPT ON Model parameter prompting is on sherpa> INSTRUMENT SOURCE 1 = RSP[instrumentAsrc] instrumentAsrc.rmf parameter value [] example.rmf instrumentAsrc.arf parameter value [] example.arf The inferred file type is ARF. If this is not what you want, please specify the type explicitly in the data command. sherpa> INSTRUMENT BACK 1 = RSP[instrumentAbkg] instrumentAbkg.rmf parameter value [] example_bkg.rmf instrumentAbkg.arf parameter value [] example_bkg.arf The inferred file type is ARF. If this is not what you want, please specify the type explicitly in the data command.
Define different source and background instrument models using specified input response files (RMF and ARF only):
sherpa> ERASE ALL sherpa> PARAMPROMPT OFF Model parameter prompting is off sherpa> INSTRUMENT SOURCE 1 = RSP[instrumentAsrc] sherpa> instrumentAsrc.rmf = example.rmf sherpa> instrumentAsrc.arf = example.arf The inferred file type is ARF. If this is not what you want, please specify the type explicitly in the data command. sherpa> INSTRUMENT BACK 1 = RSP[instrumentAbkg] sherpa> instrumentAbkg.rmf = example_bkg.rmf sherpa> instrumentAbkg.arf = example_bkg.arf The inferred file type is ARF. If this is not what you want, please specify the type explicitly in the data command.
Define different source and background instrument models using specified input response files (RMF and ARF only):
sherpa> ERASE ALL sherpa> RSP[instrumentAsrc](example.rmf, example.arf) The inferred file type is ARF. If this is not what you want, please specify the type explicitly in the data command. sherpa> INSTRUMENT SOURCE 1 = instrumentAsrc sherpa> RSP[instrumentAbkg](example_bkg.rmf, example_bkg.arf) The inferred file type is ARF. If this is not what you want, please specify the type explicitly in the data command. sherpa> INSTRUMENT BACK 1 = instrumentAbkg
Define different source and background instrument models using specified input response files (RMF and ARF only):
sherpa> ERASE ALL
sherpa> INSTRUMENT SOURCE 1 = RSP[instrumentAsrc]("data/example.rmf",
"data/example.arf")
The inferred file type is ARF. If this is not what you want, please
specify the type explicitly in the data command.
sherpa> INSTRUMENT BACK 1 = RSP[instrumentAbkg]("data/example_bkg.rmf",
"data/example_bkg.arf")
The inferred file type is ARF. If this is not what you want, please
specify the type explicitly in the data command.
Automatically define instrument models using input response files specified in dataset header(s):
sherpa> ERASE ALL
sherpa> DATA data/example.pi
The inferred file type is PHA. If this is not what you want, please
specify the type explicitly in the data command.
WARNING: statistical errors specified in the PHA file.
These are currently IGNORED. To use them, type:
READ ERRORS "<filename>[cols CHANNEL,STAT_ERR]" fitsbin
RMF is being input from:
<directory_path>/example.rmf
ARF is being input from:
<directory_path>/example.arf
Background data are being input from:
<directory_path>/example_bkg.pi
WARNING: statistical errors specified in the PHA file.
These are currently IGNORED. To use them, type:
READ ERRORS "<filename>[cols CHANNEL,STAT_ERR]" fitsbin
sherpa> SHOW
...
------------------------------
Defined analysis model stacks:
------------------------------
instrument source 1 = AutoReadResponse
instrument back 1 = AutoReadResponse
------------------------------------
Defined instrument model components:
------------------------------------
rsp1d[AutoReadResponse]
Param Type Value Min Max Units
----- ---- ----- --- --- -----
1 rmf string: "/data/simteste/Testing/sherpaTest/data/example.rmf"
2 arf string: "/data/simteste/Testing/sherpaTest/data/example.arf"
In this example, the same instrument model was automatically defined for both the source and background data, since the input data file header referenced the response files named example.rmf and example.arf.
Define an instrument model using the point-spread function contained in the file psf.fits:
sherpa> ERASE ALL sherpa> PARAMPROMPT ON Model parameter prompting is on sherpa> FPSF2D[ps1] ps1.file parameter value ["none"] psf.fits ps1.xsize parameter value [32] ps1.ysize parameter value [32] ps1.xoff parameter value [0] ps1.yoff parameter value [0] ps1.fft parameter value [1] sherpa> INSTRUMENT = ps1
The source model will be convolved with the PSF provided in the psf.fits file.
Controls the integration of model components.
sherpa> <modelname> INTEGRATE {ON | OFF}
where ![]() modelname
modelname![]() is a name that has been given to a model component by the user.
is a name that has been given to a model component by the user.
Models are integrated over bins in energy-space or wavelength-space (before being folded through an instrument), or over bins in counts-space (if no instrument model is specified). If the OFF option is chosen then, for non-binned data the model values at the entered data points are used, while for binned data the model values at the left side of the bin are used in the fitting.
This command cannot be applied to XSPEC source models or to instrument models. Also, changing the integration status of a model component will have no affect if the data are not binned.
One can use the SHOW command to determine whether a model component is currently being integrated.
The user must be careful not to define an unacceptable mixture of additive/integrated and multiplicative/non-integrated model components, such as by adding two model components with different integration statuses. Sherpa will issue a warning when it detects such an unacceptable mixture.
See also the Sherpa Manual, Chapter "Sherpa Models", Subsection "Source Model Integration".
If you create a model, e.g. a beta2d model, and turn integration off (the default for beta2d), you will get the model value at a point (x,y). In that case, the units are just "counts" since the rest of the beta2d expression is unitless (see "ahelp beta2d" for details).
When you turn integrate on, you are telling Sherpa to bin up the model values for you. Sherpa evaluates the model at (x_lo, y_lo) and (x_hi, y_hi), and bins it so that you get all the counts that happened in that bin, not just at some particular point in data space. Since the bin size is being taken into account, the value really means "counts/bin" or "counts/pixel", not simply "counts".
To see the difference that integrate makes, use the "image model" command to display the model values in ds9. Change the integrate setting and image the model again to see how the values change.
Examples:
Turn off integration for a model component:
sherpa> POW[modelc] modelc.gamma parameter value [0] modelc.ref parameter value [1] modelc.ampl parameter value [1] sherpa> modelc INTEGRATE OFF
Turn off integration for a power-law model component:
sherpa> POWLAW1D[p]
sherpa> SHOW p
powlaw1d[p] (integrate: on)
Param Type Value Min Max Units
----- ---- ----- --- --- -----
1 gamma thawed 0 -10 10
2 ref frozen 1-3.4028e+38 3.4028e+38
3 ampl thawed 1 1e-20 3.4028e+38
sherpa> p INTEGRATE OFF
sherpa> SHOW p
powlaw1d[p] (integrate: off)
Param Type Value Min Max Units
----- ---- ----- --- --- -----
1 gamma thawed 0 -10 10
2 ref frozen 1-3.4028e+38 3.4028e+38
3 ampl thawed 1 1e-20 3.4028e+38
Plots the fit statistic as a function of parameter value, using the PROJECTION algorithm. The commands INT-PROJ and INTPROJ are abbreviated equivalents.
sherpa> INTERVAL-PROJECTION [<dataset range> | ALLSETS] <arg>
where ![]() dataset range
dataset range![]()
![]() #, or more generally #:#,#:#,...,
such that # specifies a dataset number, and #:# represents an
inclusive range of datasets; one may specify multiple inclusive ranges
by separating them with commas. The default
is to create plots using data from all appropriate datasets.
#, or more generally #:#,#:#,...,
such that # specifies a dataset number, and #:# represents an
inclusive range of datasets; one may specify multiple inclusive ranges
by separating them with commas. The default
is to create plots using data from all appropriate datasets.
The command-line argument may be:
| Argument | Description |
|---|---|
| A specified model component parameter (e.g., GAUSS.pos). | |
| A specified model component parameter (e.g., g.pos). |
The user may configure INTERVAL-PROJECTION via the Sherpa state object structure intproj. The current values of the fields of this structure may be displayed using the command print(sherpa.intproj), or using the more verbose Sherpa/S-Lang module function list_intproj().
The structure fields are:
| Field | Description |
|---|---|
| fast | If 1, use a fast optimization algorithm (LEVENBERG-MARQUARDT or SIMPLEX) regardless of the current METHOD. If 0, use the current METHOD. |
| expfac | A multiplicative factor that expands the grid limits estimated by the COVARIANCE algorithm, if the grid limits are determined automatically (see arange, and below). |
| arange | If 1, the grid limits are to be determined automatically. If 0, the grid limits are specified (see min and max). |
| min | Specifies the grid minimum.
This is always a linear quantity, regardless of the setting of
log (see below).
The setting is ignored if arange |
| max | Specifies the grid maximum.
This is always a linear quantity, regardless of the setting of
log (see below).
The setting is ignored if arange |
| log | Specifies whether to use a linear (0) or logarithmic (1) spacing of grid points. |
| nloop | Specifies the number of grid points. |
| sigma | Specifies the number of |
Field values may be set using directly, e.g.,
sherpa> sherpa.intproj.arange = 0
NOTE: strict checking of value inputs is not done, i.e., the user can errantly change arrays to scalars, etc. To restore the default settings of the structure at any time, use the Sherpa/S-Lang module function restore_intproj().
The plot is created by varying each selected parameter's value on the
determined (arange ![]() 1) or specified
(arange
1) or specified
(arange ![]() 0) grid, and computing the
best-fit statistic at each grid point. INTERVAL-PROJECTION
differs from INTERVAL-UNCERTAINTY in
that all other thawed parameters are allowed to float to new best-fit
values, instead of being fixed to their best-fit values. This makes a
plot created by INTERVAL-PROJECTION a more accurate
rendering of the projected shape of statistical hypersurface, but
but causes the computation to proceed more slowly. For a fuller theoretical
description of error estimation, see PROJECTION, UNCERTAINTY, and COVARIANCE.
0) grid, and computing the
best-fit statistic at each grid point. INTERVAL-PROJECTION
differs from INTERVAL-UNCERTAINTY in
that all other thawed parameters are allowed to float to new best-fit
values, instead of being fixed to their best-fit values. This makes a
plot created by INTERVAL-PROJECTION a more accurate
rendering of the projected shape of statistical hypersurface, but
but causes the computation to proceed more slowly. For a fuller theoretical
description of error estimation, see PROJECTION, UNCERTAINTY, and COVARIANCE.
If arange ![]() 1, then the grid limits
for the plot are determined automatically using the
PROJECTION algorithm. The selected
parameter's value is varied until the fit statistic is increased by
1, then the grid limits
for the plot are determined automatically using the
PROJECTION algorithm. The selected
parameter's value is varied until the fit statistic is increased by
![]() , which is a function of
INTERVAL-PROJECTION.sigma (e.g.,
, which is a function of
INTERVAL-PROJECTION.sigma (e.g.,
![]() if the statistic is
if the statistic is ![]() and sigma
and sigma ![]() 1).
1).
The grid-point values and best-fit statistics at each grid point may be retrieved using the Sherpa/S-Lang module function get_intproj. See the examples below.
Examples:
List the current and default values of the intproj structure, and restore the default values:
sherpa> sherpa.intproj.arange = 0 sherpa> sherpa.intproj.log = 1 sherpa> sherpa.intproj.sigma = 5 sherpa> list_intproj() Parameter Current Default Description ---------------------------------------------------------------------- fast 1 1 Switch to LM/simplex: 0(n)/1(y) expfac 3 3 Expansion factor for grid arange 0 1 Auto-range: 0(n)/1(y) min 0 0 Minimum value max 0 0 Maximum value log 1 0 Log-spacing: 0(n)/1(y) nloop 20 20 Number of grid points sigma 5 1 Number of sigma sherpa> restore_intproj() sherpa> list_intproj() Parameter Current Default Description ---------------------------------------------------------------------- fast 1 1 Switch to LM/simplex: 0(n)/1(y) expfac 3 3 Expansion factor for grid arange 1 1 Auto-range: 0(n)/1(y) min 0 0 Minimum value max 0 0 Maximum value log 0 0 Log-spacing: 0(n)/1(y) nloop 20 20 Number of grid points sigma 1 1 Number of sigma
Plot ![]() within the
within the
![]() confidence interval for a fit:
confidence interval for a fit:
sherpa> READ DATA example1.dat
sherpa> PARAMPROMPT OFF
sherpa> SOURCE = POLYNOM1D[my]
sherpa> THAW my.c1 my.c2
sherpa> my.c0.min = -10
sherpa> FIT
...
sherpa> sherpa.intproj.sigma = 3
sherpa> INTERVAL-PROJECTION my.c0
Interval-Projection: computing grid size with covariance...done.
outer grid loop 20% done...
outer grid loop 40% done...
outer grid loop 60% done...
outer grid loop 80% done...\end{verbatim}
\item \label{interval-projection-ex3}
Plot $\chi^2$ for the same fit within
manually set grid limits:
\begin{verbatim}sherpa> sherpa.intproj.arange = 0
sherpa> sherpa.intproj.min = -25
sherpa> sherpa.intproj.max = 25
sherpa> INTERVAL-PROJECTION my.c0
Interval-Projection: grid size set by user.
outer grid loop 20% done...
outer grid loop 40% done...
outer grid loop 60% done...
outer grid loop 80% done...\end{verbatim}
\item \label{interval-projection-ex4}
Save the results of \texttt{INTERVAL-PROJECTION} to an ASCII file:
\begin{verbatim}[...run INTERVAL-PROJECTION...]
sherpa> my_var = get_intproj()
sherpa> writeascii("my_output.dat",my_var.x0,my_var.y)
sherpa> quit
Goodbye.
unix> more my_output.dat
-25 34.2524
-22.3684 27.5464
-19.7368 21.5764
...
Plots the fit statistic as a function of parameter value, using the UNCERTAINTY algorithm. The commands INT-UNC and INTUNC are abbreviated equivalents.
sherpa> INTERVAL-UNCERTAINTY [<dataset range> | ALLSETS] <arg>
where ![]() dataset range
dataset range![]()
![]() #, or more generally #:#,#:#,...,
such that # specifies a dataset number, and #:# represents an
inclusive range of datasets; one may specify multiple inclusive ranges
by separating them with commas. The default
is to create plots using data from all appropriate datasets.
#, or more generally #:#,#:#,...,
such that # specifies a dataset number, and #:# represents an
inclusive range of datasets; one may specify multiple inclusive ranges
by separating them with commas. The default
is to create plots using data from all appropriate datasets.
The command-line argument may be:
| Argument | Description |
|---|---|
| A specified model component parameter (e.g., GAUSS.pos). | |
| A specified model component parameter (e.g., g.pos). |
The user may configure INTERVAL-UNCERTAINTY via the Sherpa state object structure intunc. The current values of the fields of this structure may be displayed using the command print(sherpa.intunc), or using the more verbose Sherpa/S-Lang module function list_intunc().
The structure fields are:
| Field | Description |
|---|---|
| arange | If 1, the grid limits are to be determined automatically. If 0, the grid limits are specified (see min and max). |
| min | Specifies the grid minimum.
This is always a linear quantity, regardless of the setting of
log (see below).
The setting is ignored if arange |
| max | Specifies the grid maximum.
This is always a linear quantity, regardless of the setting of
log (see below).
The setting is ignored if arange |
| log | Specifies whether to use a linear (0) or logarithmic (1) spacing of grid points. |
| nloop | Specifies the number of grid points. |
| sigma | Specifies the number of |
Field values may be set using directly, e.g.,
sherpa> sherpa.intunc.arange = 0
NOTE: strict checking of value inputs is not done, i.e., the user can errantly change arrays to scalars, etc. To restore the default settings of the structure at any time, use the Sherpa/S-Lang module function restore_intunc().
The plot is created by varying each selected parameter's value on an automatically determined grid, and computing the best-fit statistic at each grid point. INTERVAL-UNCERTAINTY differs from INTERVAL-PROJECTION in that all other thawed parameters are fixed to their best-fit values, instead of being allowed to float to new best-fit values. This makes a plot created by INTERVAL-UNCERTAINTY a less accurate rendering of the projected shape of statistical hypersurface, but it can be faster to create. For a fuller theoretical description of error estimation, see PROJECTION, UNCERTAINTY, and COVARIANCE.
The grid limits for the plot are determined automatically using the
UNCERTAINTY algorithm. Each
parameter's value is varied until the fit statistic is increased by
![]() , which is a function of
sigma (e.g.,
, which is a function of
sigma (e.g.,
![]() if the statistic is
if the statistic is
![]() and sigma
and sigma ![]() 1).
1).
The grid-point values and best-fit statistics at each grid point may be retrieved using the Sherpa/S-Lang module function get_intunc. See the examples below.
Examples:
List the current and default values of the intunc structure, and restore the default values:
sherpa> sherpa.intunc.arange = 0 sherpa> sherpa.intunc.log = 1 sherpa> sherpa.intunc.sigma = 5 sherpa> list_intunc() Parameter Current Default Description ---------------------------------------------------------------------- arange 0 1 Auto-range: 0(n)/1(y) min 0 0 Minimum value max 0 0 Maximum value log 1 0 Log-spacing: 0(n)/1(y) nloop 100 100 Number of grid points sigma 5 1 Number of sigma sherpa> restore_intunc() sherpa> list_intunc() Parameter Current Default Description ---------------------------------------------------------------------- arange 1 1 Auto-range: 0(n)/1(y) min 0 0 Minimum value max 0 0 Maximum value log 0 0 Log-spacing: 0(n)/1(y) nloop 100 100 Number of grid points sigma 1 1 Number of sigma
Plot ![]() within the
within the
![]() confidence interval for a fit:
confidence interval for a fit:
sherpa> READ DATA example1.dat
sherpa> PARAMPROMPT OFF
sherpa> SOURCE = POLYNOM1D[my]
sherpa> THAW my.c1 my.c2
sherpa> my.c0.min = -10
sherpa> FIT
...
sherpa> sherpa.intunc.sigma = 3
sherpa> INTERVAL-UNCERTAINTY my.c0
Interval-Uncertainty: computing grid size with uncertainty...done.
outer grid loop 20% done...
outer grid loop 40% done...
outer grid loop 60% done...
outer grid loop 80% done...\end{verbatim}
\item \label{interval-uncertainty-ex3}
Save the results of \texttt{INTERVAL-UNCERTAINTY} to an ASCII file:
\begin{verbatim}[...run INTERVAL-UNCERTAINTY...]
sherpa> my_var = get_intunc()
sherpa> writeascii("my_output.dat",my_var.x0,my_var.y)
sherpa> quit
Goodbye.
unix> more my_output.dat
-4.17797 9.25601
-4.08741 8.89599
-3.99684 8.54331
...
Turns on/off the writing of all commands to a file.
sherpa> JOURNAL {<filename> | OFF }
where ![]() filename
filename![]() is the name given to the
ASCII file that is written. The command
JOURNAL OFF terminates writing to the
file. By default, writing of all commands to a file
is turned off.
is the name given to the
ASCII file that is written. The command
JOURNAL OFF terminates writing to the
file. By default, writing of all commands to a file
is turned off.
Examples:
Write all commands to a file:
sherpa> JOURNAL tmpfil
This command initiates writing a record of all commands to the file tmpfil.
Turn off writing of all commands to a file:
sherpa> JOURNAL OFF
This command terminates writing to the file tmpfil.
Causes the specified 1-D data to be displayed, via ChIPS.
sherpa> LPLOT [<num_plots>] <arg_1> [# [ID]] [<arg_2> [# [ID]] ...]
![]() num_plots
num_plots![]() specifies the number of plotting windows to
open within the ChIPS pane (default 1); that number sets the
number of subsequent arguments. For each subsequent argument,
# specifies the number of the dataset
(default dataset number is 1),
and the ID modifier is used
for displaying background datasets,
and then if and only if
the Sherpa state
object variable multiback is set to 1,
i.e., if more than
one background dataset is to be associated with a single source dataset.
The ID modifier may be any unreserved string
(e.g., A, foo, etc.), i.e.,
a string that is not a parsable command.
specifies the number of plotting windows to
open within the ChIPS pane (default 1); that number sets the
number of subsequent arguments. For each subsequent argument,
# specifies the number of the dataset
(default dataset number is 1),
and the ID modifier is used
for displaying background datasets,
and then if and only if
the Sherpa state
object variable multiback is set to 1,
i.e., if more than
one background dataset is to be associated with a single source dataset.
The ID modifier may be any unreserved string
(e.g., A, foo, etc.), i.e.,
a string that is not a parsable command.
The argument ![]() arg_n
arg_n![]() may be any of the following:
may be any of the following:
| Argument | Displays |
|---|---|
| {{DATA |
The source |
| {UDATA |
The unconvolved source |
| {ERRORS |
The estimated total errors for the source |
| {SYSERRORS |
The assigned systematic errors for the source |
| {STATERRORS |
The estimated statistical errors for the source |
| {{MODEL |
The (convolved) source |
| {FIT |
The data (with errors) and model for source |
| {UFIT |
The unconvolved data (with errors) and source model for source |
| {DELCHI |
The sigma residuals of the source |
| {RESIDUALS |
The absolute residuals of the source |
| {RATIO |
The ratio (data/model) for source |
| {CHI SQU |
The contributions to the |
| {STATISTIC |
The contributions to the current statistic
from each source |
| {WEIGHT |
The statistic weight value assigned to each source |
| {FILTER |
The mask value (0 |
| {GROUP |
The grouping value (1 |
| {QUALITY |
The quality value (0 |
| The (unconvolved) model amplitudes for the
specified model stack (SOURCE,
{BACKGROUND |
|
| The (unconvolved) model amplitudes for the specified user-defined model stack | |
| The (unconvolved) amplitudes of the specified model component (e.g., GAUSS) | |
| The (unconvolved) amplitudes of the specified model component (e.g., g) | |
| {ARF |
The unfiltered source |
| {PSF |
The unfiltered source |
If there is no open plotting window when an LPLOT command is given, one will be created automatically.
Related commands include:
The appearance of plots generated with this command can be changed by modifying the fields of certain state objects. See the ahelp for Sherpa or for sherpa.plot for more information.
NOTE: all ChIPS commands may be used from within Sherpa to modify plot characteristics. In order to view these changes, the REDRAW command must be issued.
See the display chapter for more information regarding data display capabilities, including modifying various plot characteristics.
Examples:
Display 1-D data:
sherpa> DATA 3 example.dat sherpa> LPLOT DATA 3
The last command plots dataset number 3. Dataset number 3 must be a 1-D dataset.
Exclude a data range and display the filtered range:
sherpa> DATA example.dat sherpa> IGNORE ALL sherpa> NOTICE FILTER 2:70 sherpa> LPLOT FILTER
The command IGNORE ALL clears any previous filters, then the next command defines a filter for dataset number 1. The last command displays the defined filter.
Exclude a background data range and display the filtered background range:
sherpa> DATA example.dat sherpa> BACK example_bkg.dat sherpa> IGNORE BACK ALL sherpa> NOTICE BACK FILTER 2:70 sherpa> LP BFILTER
The command IGNORE BACK ALL clears any previous background filters, and the next command defines a filter for the background of dataset number 1. The last command displays the defined background filter.
Have plotted data written to output data files:
sherpa> ERASE ALL sherpa> DATA data/example1a.dat sherpa> sherpa.dataplot.x_errorbars = 0 sherpa> sherpa.dataplot.y_errorbars = 0 sherpa> LPLOT DATA sherpa> STORE myplot1.chp sherpa> SAVE ALL mysession1.shp sherpa> ls myplot1.chp* myplot1.chp myplot1.chp.fits sherpa> ls mysession1.shp* mysession1.shp sherpa> EXIT Goodbye.
The STORE command (a ChIPS command) specifies that a record of the commands used to generate the plot be saved in an ASCII file named myplot1.chp. The command SAVE ALL mysession1.shp is useful for saving the current state of the Sherpa session; it may then be restored at a later time.
This example also shows the use of a state object to modify the appearance of a plot (see the ahelp for sherpa.dataplot for more information).
Display 1-D data, the fit, and the fit residuals, using two windows:
sherpa> DATA example.dat sherpa> PARAMPROMPT OFF Model parameter prompting is off sherpa> POW[modela] sherpa> SOURCE = modela sherpa> FIT 1 sherpa> LPLOT 2 FIT RESIDUALS
This command displays a plot with the data and source model together in the first window, and a plot with the residuals of the fit in the second window.
Display 1-D data and fit, for two different datasets, using two windows:
sherpa> DATA 2 example2.dat sherpa> LPLOT 2 DATA 1 DATA 2
This command displays a plot with dataset number 1 in the first window, and dataset number 2 in the second window. The following commands are all equivalent:
sherpa> LP 2 DATA 1 DATA 2 sherpa> LP 2 DATA 1:2 sherpa> LP 2 DATA ALL
Display 1-D fit and residuals for first dataset, and also display second dataset:
sherpa> LP 3 FIT 1 RESIDUALS 1 DATA 2
This command displays a plot with dataset number 1 and its fit in the first window, the residuals in the second window, and dataset number 2 in the third window.
Plot multiple datasets:
sherpa> ERASE ALL sherpa> DATA 1 data/example1.dat sherpa> DATA 2 data/example2.dat sherpa> DATA 3 data/example3.dat sherpa> DATA 4 data/example4.dat sherpa> LPLOT 4 DATA ALL
This LPLOT command plots all of the datasets, each dataset in a window - dataset number 1 in the first window, dataset number 2 in the second window, etc. In this example, the following command produces the same result:
sherpa> LPLOT 4 DATA 1:4
Calculates the sum of convolved model amplitudes for source or background datasets.
sherpa> [B]MCOUNTS [# [ID]] [{(<value>) | (<min>:<max>) | (<region descriptor>)} ] \
[ {(<model component>) | (<model stack>)} ]
MCOUNTS is used for summing source model counts, while BMCOUNTS is used for summing background model counts.
# specifies the dataset over which the source model is evaluated. The ID modifier is used only for summing background counts, and then if and only if the Sherpa state object variable multiback is set to 1, i.e., if more than one background dataset is to be associated with a single source dataset. The ID modifier may be any unreserved string (e.g., A, foo, etc.), i.e., a string that is not a parsable command.
The default is to do summations for all appropriate datasets (i.e., those for which source/background expressions have been defined). The summation may be computed at one energy/wavelength, over a range of energies/wavelengths, or within a 2-D region, with the default being to compute the flux the total available range.
The summation may also be computed for individual model components, or for previously defined model stacks, with the default being to compute the summation using all model components in the SOURCE or BACKGROUND expression.
A source or background model stack must be defined before a respective flux can be computed; see the SOURCE and BACKGROUND commands. This is true even if one computes the flux of an individual model component or of models defined in a model stack. (This limitation will be removed in a future version of Sherpa.)
For 1-D data, if
For 2-D data, if a region descriptor is given, then the summation of model counts within that region is returned; otherwise, the summation is carried out over the entire input image.
Tip: To perform background subtraction in Sherpa, the command SUBTRACT must be issued; this is in contrast to XSPEC, which performs background subtraction automatically.
The summation of model counts may be done using the Sherpa/S-Lang module functions get_mcounts_sum and get_bmcounts_sum.
Examples:
Calculate the summation of model counts over the full energy range:
sherpa> MCOUNTS Model counts for source dataset 1: 1014.89 counts
Calculate the summation of background model counts over the range 2 to 10 keV. If the areas of the source and background extraction regions are different (as manifested by differences in, e.g., the BACKSCAL keywords in the headers of the source and background data files), then the number of expected background counts in the source region will also be shown.
sherpa> BMCOUNTS (2.0:10.0)
Model counts for background dataset 1: 456.003 counts
...scaled to source region: 140.496 counts
Calculate the summation of model counts at a single energy (2.0 keV) for the power-law component of a source expression:
sherpa> SOURCE 1 = XSWABS[A] * POW[P] sherpa> MCOUNTS 1 (2.0) P Model counts for source dataset 1: 1.07005 counts
Calculate the summation of model counts over the energy range 2.0 to 4.0 keV for a model stack:
sherpa> FOO = POW[P] + GAUSS[G] sherpa> SOURCE 1 = XSWABS[A] * FOO sherpa> MCOUNTS 1 (2:4) FOO Model counts for source dataset 1: 83.346 counts
Calculate the summation of model counts within circles of radius 5 and 10 in a 2-D image (note, the quotes are necessary):
sherpa> SOURCE = GAUSS2D[G] sherpa> MCOUNTS 1 "CIRCLE(247,257,5)" Flux for source dataset 1: 1614.79 counts sherpa> MCOUNTS 1 "CIRCLE(247,257,10)" Flux for source dataset 1: 3142.15 counts
Specifies the optimization method. The command SEARCHMETHOD is equivalent.
sherpa> {METHOD | SEARCHMETHOD} <sherpa_methodname>
The following optimization methods are featured in Sherpa:
| Description | |
|---|---|
| GRID | A grid search of parameter space, with no optimization. |
| GRID-POWELL | A grid search of parameter space, with optimization done starting from each grid point, using the Powell method. |
| {LEVENBERG-MARQUARDT |
Levenberg-Marquardt optimization. |
| MONTECARLO | A Monte Carlo search of parameter space, with no optimization. |
| MONTE-LM | A Monte Carlo search of parameter space, with optimization done starting from each randomly selected point, using the LEVENBERG-MARQUARDT method. |
| MONTE-POWELL | A Monte Carlo search of parameter space, with optimization done starting from each randomly selected point, using the POWELL method. |
| POWELL | Powell optimization. |
| {SIGMA-REJECTION |
Optimization combined with data cleansing: outliers are filtered from the data. |
| SIMPLEX | Simplex optimization. |
| SIMUL-ANN-1 | A simulated annealing search, with one parameter varied at each step and no optimization. |
| SIMUL-ANN-2 | A simulated annealing search, with all parameters varied at each step and no optimization. |
| SIMUL-POW-1 | A combination of SIMUL-ANN-1 with POWELL optimization. |
| SIMUL-POW-2 | A combination of SIMUL-ANN-2 with POWELL optimization. |
| USERMETHOD | A user-defined method of optimization. |
The default optimization method in CIAO 3.0 is LEVENBERG-MARQUARDT.
The current optimization method, and its parameter names and values, may be listed with the command SHOW METHOD. Values for these optimization parameters may be set individually using one of the following command syntax options:
sherpa> <sherpa_methodname>.<paramname> = <value> sherpa> <sherpa_methodname>.<paramname>.VALUE = <value> sherpa> <sherpa_methodname>.<#> = <value> sherpa> <sherpa_methodname>.<#>.VALUE = <value>
where:
Parameter listings for each optimization method are given
in the Sherpa Methods chapter. (Alternatively, one may
peruse the documentation for each ![]() sherpa_methodname
sherpa_methodname![]() .)
.)
The user may access a string giving the name of the current optimization method via the Sherpa/S-Lang module function get_method_expr.
Examples:
Specify an optimization method to be used; set an optimization parameter value:
sherpa> METHOD POWELL
sherpa> SHOW METHOD
Optimization Method: Powell
Name Value Min Max Description
---- ----- --- --- -----------
1 iters 2000 1 10000 Maximum number of iterations
2 eps 1e-06 1e-09 1e-03 Fractional accuracy
3 tol 1e-06 1e-08 0.1 Tolerance in lnmnop
4 huge 1e+10 1000 1e+12 Fractional accuracy
sherpa> POWELL.eps = .0009
sherpa> SHOW METHOD
Optimization Method: Powell
Name Value Min Max Description
---- ----- --- --- -----------
1 iters 2000 1 10000 Maximum number of iterations
2 eps 9e-04 1e-09 1e-03 Fractional accuracy
3 tol 1e-06 1e-08 0.1 Tolerance in lnmnop
4 huge 1e+10 1000 1e+12 Fractional accuracy
Set an optimization parameter value:
sherpa> POWELL.1 = 100
sherpa> SHOW METHOD
Optimization Method: Powell
Name Value Min Max Description
---- ----- --- --- -----------
1 iters 100 1 10000 Maximum number of iterations
2 eps 1e-06 1e-09 1e-03 Fractional accuracy
3 tol 1e-06 1e-08 0.1 Tolerance in lnmnop
4 huge 1e+10 1000 1e+12 Fractional accuracy
Set an optimization parameter value:
sherpa> POWELL.eps.VALUE = .0007
sherpa> SHOW METHOD
Optimization Method: Powell
Name Value Min Max Description
---- ----- --- --- -----------
1 iters 2000 1 10000 Maximum number of iterations
2 eps 7e-04 1e-09 1e-03 Fractional accuracy
3 tol 1e-06 1e-08 0.1 Tolerance in lnmnop
4 huge 1e+10 1000 1e+12 Fractional accuracy
Set an optimization parameter value:
sherpa> POWELL.1.VALUE = 100
sherpa> SHOW METHOD
Optimization Method: Powell
Name Value Min Max Description
---- ----- --- --- -----------
1 iters 100 1 10000 Maximum number of iterations
2 eps 1e-06 1e-09 1e-03 Fractional accuracy
3 tol 1e-06 1e-08 0.1 Tolerance in lnmnop
4 huge 1e+10 1000 1e+12 Fractional accuracy
Computes significance using the Maximum Likelihood Ratio test.
sherpa> MLR <delta_dof> <delta_stat>
The command arguments are:
| Argument | Description |
|---|---|
| The difference in the number of degrees of freedom (dofs) between the fits of the null and alternative (more complex) hypotheses. | |
| The difference in the best-fit statistics between the two fits. |
The Maximum Likelihood Ratio (MLR) test is a model comparison test.
Model comparison tests are used to select from two competing models
that which best describes a particular dataset. A model comparison
test statistic ![]() is created from the best-fit
statistics of each fit;
as with all statistics, it is sampled from a probability distribution
is created from the best-fit
statistics of each fit;
as with all statistics, it is sampled from a probability distribution
![]() . The test significance is defined as the
integral of
. The test significance is defined as the
integral of ![]() from the observed value of
from the observed value of ![]() to infinity. The
significance
quantifies the probability that one would select the more complex
model when in fact the null hypothesis is correct. A standard
threshold for selecting the more complex model is significance
to infinity. The
significance
quantifies the probability that one would select the more complex
model when in fact the null hypothesis is correct. A standard
threshold for selecting the more complex model is significance ![]() 0.05 (the "95% criterion" of statistics).
0.05 (the "95% criterion" of statistics).
The MLR test may be used if:
If these conditions are fulfilled, then the change in statistic from
one fit to the other (![]() delta_stat
delta_stat![]() )
is sampled from the
)
is sampled from the ![]() distribution for
distribution for ![]() delta_dof
delta_dof![]() degrees of freedom.
If these conditions
are not fulfilled, then the MLR test significance may not be accurate.
degrees of freedom.
If these conditions
are not fulfilled, then the MLR test significance may not be accurate.
The MLR test significance can also be retrieved using the Sherpa/S-Lang module function get_mlr.
Examples:
Perform the Maximum Likelihood Ratio test.
Fit two models to the data, one with two more parameters than the
other. The improvement in
![]() (or the Cash statistic) is
20.0. Determine the significance by computing the tail integral
of the
(or the Cash statistic) is
20.0. Determine the significance by computing the tail integral
of the ![]() distribution for 2 degrees of freedom from 20.0 to infinity:
distribution for 2 degrees of freedom from 20.0 to infinity:
sherpa> MLR 2 20.00 significance = 4.53999e-05
If this significance is smaller than the predefined threshold for accepting the more complex model (e.g., 0.05), then the more complex model is selected. Otherwise, the null hypothesis is selected.
Specifies a data portion to be included, for 1- or 2-D data.
sherpa> NOTICE [{SOURCE | BACK}] [<dataset range> | ALLSETS] [ID] <arg>
where ![]() dataset range
dataset range![]()
![]() #, or more
generally #:#,#:#,..., such that # specifies
a dataset number, and #:# represents an inclusive range
of datasets; one may specify multiple inclusive ranges by separating
them with commas. The default dataset is dataset 1.
#, or more
generally #:#,#:#,..., such that # specifies
a dataset number, and #:# represents an inclusive range
of datasets; one may specify multiple inclusive ranges by separating
them with commas. The default dataset is dataset 1.
The modifiers SOURCE and BACK may be used to specify that the filter is to be applied to either the source or background data only. If neither is specified, then the filter is applied to both the source and background datasets. Note that in CIAO 3.1 when omitting the modifiers the definition of INSTRUMENT BACK is required for filtering PHA data in energy/wave if either background file or background models have been defined.
The ID modifier is used only for the command IGNORE BACK (see below), and even then if and only if the Sherpa state object variable multiback is set to 1, i.e., if more than one background dataset is to be associated with a single source dataset. The ID modifier may be any unreserved string (e.g., A, foo, etc.), i.e., a string that is not a parsable command.
![]() arg
arg![]() is either:
is either:
| Argument | To include: |
|---|---|
| ALL | The entire dataset. |
| FILTER |
Bins with x-values satisfying |
| {BINS |
Bins whose sequential numbers satisfy |
| ENERGY |
Bins with x-values in energy space satisfying |
| WAVE |
Bins with x-values in wavelength space satisfying |
| PLOT | A range selected interactively from an open plot (1-D only). |
| IMAGE | A region selected interactively from an open image (2-D only). |
| {IMAGE |
Pixels with logical coordinates satisfying |
| PHYSICAL |
Pixels with physical coordinates satisfying |
| {WCS |
Pixels with world coordinates satisfying |
The typical ![]() filterExpr
filterExpr![]() for 1-D data is the
range filter:
for 1-D data is the
range filter:
| This Filter Expression: | Means: |
|---|---|
| #:# | Include all data from the first value to the second value, inclusive. |
| #: | Include all data above the given value, inclusive. |
| :# | Include all data below the given value, inclusive. |
| # | Include the data point corresponding to the given value. |
For 2-D data, ![]() filterExpr
filterExpr![]() is a quote-delimited region
specification. See "ahelp dmregions" for more information on
allowed region specifications.
is a quote-delimited region
specification. See "ahelp dmregions" for more information on
allowed region specifications.
For more information on filter expressions, see the
Sherpa Filtering
Chapter for the full
![]() filterExpr
filterExpr![]() definition, as well as information
regarding other filtering methods.
definition, as well as information
regarding other filtering methods.
The difference between the arguments FILTER and
{BINS ![]() CHANNELS} may be
illustrated with the following simplistic ASCII dataset:
CHANNELS} may be
illustrated with the following simplistic ASCII dataset:
x y - - 22.6 10 22.7 9 22.8 12 22.9 7
The command NOTICE FILTER 22.65:22.85 will cause the middle two bins to be included in the filter. This is equivalent to NOTICE BINS 2:3, i.e., notice the 2nd and 3rd bins. For PHA datasets, NOTICE FILTER and NOTICE BINS will lead to the same result, since the x-values of the PHA channels are sequential integers: 1, 2, 3...
To use the commands NOTICE ENERGY or NOTICE WAVE, a PHA dataset must have been read in, and an INSTRUMENT model stack defined. Note that regardless of the current ANALYSIS setting, one may filter using either NOTICE ENERGY or NOTICE WAVE. See the examples below.
To specify regions to notice within an image:
Verify results using IMAGE FILTER.
To specify regions to notice within a plot:
Ranges/regions to be notices may be alternatively set using the Sherpa/S-Lang module functions set_notice and set_notice2d, et al.
Examples:
Include all data values:
sherpa> DATA example.dat sherpa> NOTICE ALL
The last command tells Sherpa to use all data in dataset 1.
Include a particular data range from the source, background, or both:
sherpa> DATA data/data.dat sherpa> BACK data/data_bckg.dat sherpa> IGNORE SOURCE ALL sherpa> NOTICE SOURCE FILTER 5:10 sherpa> LPLOT 2 DATA BACK
After the input of source and background data, the command NOTICE SOURCE FILTER 5:10 tells Sherpa to include those bins in the source dataset whose x-axis values are equal to 5 through 10, inclusive. Note that the preceding IGNORE SOURCE ALL command is not strictly necessary, but is included here for completeness. See the Sherpa Filtering Chapter for further examples of filter expressions and usage of the IGNORE command. With the final command, a plot of both the source and background data illustrates that the filter was applied to the source data only; the background data remains unfiltered.
sherpa> NOTICE ALL sherpa> IGNORE BACK ALL sherpa> NOTICE BACK FILTER 5:10 sherpa> LPLOT 2 DATA BACK sherpa> LPLOT BFILTER
The NOTICE ALL command eliminates any filters applied to the source and background datasets. The command NOTICE BACK FILTER 5:10 tells Sherpa to include those bins in the background dataset whose x-axis values are equal to 5 through 10, inclusive. Note that the preceding IGNORE BACK ALL command is not strictly necessary, but is included here for completeness. With the first LPLOT command, a plot of both the source and background data illustrates that the filter was applied to the background data only; the source data remains unfiltered. The final command plots the filter status of each background data point.
sherpa> IGNORE ALL sherpa> NOTICE FILTER 5:10 sherpa> LPLOT 2 DATA BACK sherpa> LPLOT FILTER
The NOTICE FILTER 5:10 command tells Sherpa to exclude those bins in both the source and background datasets whose x-axis values are equal to 5 through 10, inclusive. Note that the preceding IGNORE ALL command is not strictly necessary, but is included here for completeness. With the first LPLOT command, a plot of both the source and background data illustrates that the filter was applied to both datasets. The final command plots the filter status of each source data point.
Include a 2-D region, specified from an image display:
sherpa> READ DATA example_img.fits sherpa> IMAGE DATA sherpa> IGNORE ALL <mark include region(s)> sherpa> NOTICE IMAGE sherpa> IMAGE FILTER
In this example, 2-D image data is first displayed. Then the data filter is set to exclude the entire image, with the command NOTICE ALL. (This command is not needed in this particular example but is shown for completeness.) Next, the user chooses regions, by placing include markers on the displayed image. The command NOTICE IMAGE sets the data filter to exclude data within the marked regions. The command IMAGE FILTER displays the resulting filter.
Include a 1-D data range, specified from a plot display:
sherpa> READ DATA example.dat sherpa> LPLOT DATA sherpa> IGNORE ALL sherpa> NOTICE PLOT <left-mouse-click once at the desired minimum x-axis value> <and then left-mouse-click again at the desired maximum x-axis value> sherpa> LPLOT FILTER sherpa> LPLOT DATA
In this example, 1-D data is first displayed. Then the data filter is set to exclude the entire dataset, with the command IGNORE ALL. (This command is not needed in this particular example but is shown for completeness.) The command NOTICE PLOT readies the cursor for selecting the desired filter region, and the user should then left-mouse-click first at the desired minimum x-axis location and then again at the maximum x-axis location. After the second left-mouse-click, the Sherpa command prompt is returned. The command LPLOT FILTER will then plot the data region that you have marked for inclusion. Finally, the dataset is plotted again, with the command LPLOT DATA, showing that the selected regions have been properly included.
Include a 1-D data range, specified from a plot display, for dataset number 2:
sherpa> READ DATA 1 example1.dat sherpa> READ DATA 2 example2.dat sherpa> LPLOT DATA 2 sherpa> IGNORE 2 ALL sherpa> NOTICE 2 PLOT <left-mouse-click once at the desired minimum x-axis value> <and then left-mouse-click again at the desired maximum x-axis value> sherpa> LPLOT FILTER 2 sherpa> LPLOT DATA 2 sherpa> sherpa> IGNORE ALL sherpa> NOTICE PLOT <left-mouse-click once at the desired minimum x-axis value> <and then left-mouse-click again at the desired maximum x-axis value> sherpa> LPLOT FILTER sherpa> LPLOT DATA
In this example, two 1-D datasets are input, and dataset number 2 is first displayed. Then, the data filter is set to exclude all of dataset number 2, with the command IGNORE 2 ALL. (This command is not needed in this particular example but is shown for completeness.) The command NOTICE 2 PLOT readies the cursor for selecting the desired filter region for dataset number 2, and the user should then left-mouse-click first at the desired minimum x-axis location and then again at the maximum x-axis location. After the second left-mouse-click, the Sherpa command prompt is returned. The command LPLOT FILTER 2 will then plot the data region that you have marked for inclusion from dataset number 2. Finally, dataset number 2 is plotted again, with the command LPLOT DATA 2, showing that the selected regions have been properly included.
Next, the user sets the data filter to exclude all of dataset number 1, with the command IGNORE ALL. (This command is not needed in this particular example but is shown for completeness.) The command NOTICE PLOT readies the cursor for selecting the desired filter region for dataset number 1, and the user should then left-mouse-click first at the desired minimum x-axis location and then at the maximum x-axis location (from the plot that's currently displayed of dataset number 2). The command LPLOT FILTER will then plot the data region that you have marked for inclusion from dataset number 1. Finally, dataset number 1 is plotted again, with the command LPLOT DATA, showing that the selected regions have been properly included. Note that dataset number 1 was interactively filtered, from a display of dataset number 2.
Include particular data values and ranges:
sherpa> DATA 3 example.dat sherpa> IGNORE 3 ALL sherpa> NOTICE 3 FILTER 4, 8:, 1:3
The first command, IGNORE 3 ALL, sets all of dataset number 3 to be excluded. (This command is not needed in this particular example but is shown for completeness.) The second command uses a filter expression to include those x-axis data values that are equal to 4, greater-than or equal to 8, or equal to 1 thru 3, inclusive. See the Sherpa Filtering Chapter for further examples of filter expressions and usage of the NOTICE command.
Filter PHA data by energy, or wavelength:
sherpa> ERASE ALL sherpa> DATA example.pha The inferred file type is PHA. If this is not what you want, please specify the type explicitly in the data command. WARNING: using systematic errors specified in the PHA file. RMF is being input from: <directory_path>/example.rmf ARF is being input from: <directory_path>/example.arf Background data are being input from: <directory_path>/example_bkg.pha sherpa> ANALYSIS ENERGY sherpa> IGNORE ALL sherpa> NOTICE ENERGY 5:10 sherpa> LPLOT DATA sherpa> IGNORE ALL sherpa> NOTICE WAVE 0:20 sherpa> ANALYSIS WAVE sherpa> LPLOT DATA
In this example, the dataset is filtered using NOTICE WAVE even though the ANALYSIS setting is ENERGY. This is possible because header information in the data file allowed for an instrument model to be automatically defined when the data were initially read.
Include a 2-D region specified from the command line, in physical coordinates:
sherpa> DATA data/example_img2.fits sherpa> NOTICE PHYSICAL "CIRCLE(4010,3928,100)" sherpa> IMAGE FILTER
To filter in physical coordinates requires no action on the part of the user beyond specifying the PHYSICAL modifier; Sherpa automatically performs the image-to-physical coordinate conversion (if it can). Note that the quote marks are required in CIAO 3.0 when specifying 2-D filter regions. (They are not required when specifying 1-D regions, as seen in the other examples above.) The command IMAGE FILTER displays the resulting filter.
Opens the image display window.
sherpa> OPEN IMAGE
where IMAGE is the imaging window (see the IMAGE command).
Note: If there is no open imaging window, giving any IMAGE command will lead to the creation of one. Similarly, if there is no open plotting window, giving a LPLOT, CPLOT, or SPLOT command will lead to the creation of one.
See the CLOSE command for information on closing an image display window. Note also that image display windows, as well as plotting display windows, may be closed simply by closing the window with a mouse click.
See the Sherpa Display Chapter for further information regarding data display capabilities within Sherpa.
Examples:
Causes multiple data curves to be displayed in the same drawing area, via ChIPS.
sherpa> OPLOT <arg_1> [# [ID]] [<arg_2> [# [ID]] ...]
# specifies the number of the dataset (default is 1). The ID modifier is used to display background datasets, if and only if the Sherpa state object variable multiback is set to 1 (i.e. if more than one background dataset is to be associated with a single source dataset). The ID modifier may be any string that is not a parsable command (e.g. "A", "bob", "foo").
The allowed arguments ![]() arg_n
arg_n![]() are listed in the
documentation for LPLOT. The exceptions to
that information are the FIT plots: if used in the
OPLOT command, only the data is displayed, not the
data and the model.
are listed in the
documentation for LPLOT. The exceptions to
that information are the FIT plots: if used in the
OPLOT command, only the data is displayed, not the
data and the model.
The appearance of plots generated with this command can be changed by modifying the fields of certain state objects. See the ahelp for Sherpa or for sherpa.plot for more information.
When using ChIPS commands to modify plot characteristics from within Sherpa, the REDRAW command must be issued in order to view the changes.
Examples:
Overplot two sets of 1-D data:
sherpa> DATA data/example1.dat sherpa> DATA 2 data/example2.dat sherpa> OPLOT DATA 1 DATA 2
In this example, a fit is read in from a saved Sherpa session. Then the data, individual model components of the multi-component model, and the sum of the individual model components are plotted:
sherpa> use fit.shp sherpa> oplot ufit source galabs powhard sherpa> c 2 red sherpa> c 3 green sherpa> c 4 blue sherpa> log sherpa> redraw
The model components "galabs" and "powhard" are defined in fit.shp. After plotting, the curves are given different colors to differentiate them, and the plot is changed to log scale.
Turns on/off prompting for model parameter values.
sherpa> PARAMPROMPT {ON | OFF}
By default, prompting for model parameter values is ON.
However, when an Sherpa script file name is provided on the UNIX command line
(e.g. unix![]() sherpa example.script) or is provided as the
argument of a USE command,
prompting for model parameter values is automatically turned off.
sherpa example.script) or is provided as the
argument of a USE command,
prompting for model parameter values is automatically turned off.
For more information about parameter prompting, see the CREATE command.
Examples:
Turn off parameter prompting; set parameter values using the model language syntax:
sherpa> PARAMPROMPT OFF Model parameter prompting is off sherpa> SOURCE 2 = POW[modele] sherpa> modele.ampl = 2.3
Call and execute Sherpa script; set parameter values using the model language syntax:
sherpa> $more example.script
# This is my sherpa script
READ DATA example.dat
POLY[modela]
SOURCE = modela
FIT
sherpa> USE example.script
powll: v1.2
powll: initial function value = 3.25453E+02
powll: converged to minimum = 9.80351E+01 at iteration = 2
powll: final function value = 9.80351E+01
modela.c0 10.4657
sherpa>
This example shows that when a Sherpa script is called and executed, prompting for model parameter values is automatically turned off.
![]() REMOVED AS OF CIAO 3.0.2
REMOVED AS OF CIAO 3.0.2![]() Sets the unit type for the x-axis of a plot.
Sets the unit type for the x-axis of a plot.
This command was removed from CIAO at version 3.0.2.
The PLOTX command has been disabled in order to lessen confusion in visualization. Plots are done using the ANALYSIS setting, if applicable, and in channels otherwise; see "ahelp analysis" for more information.
NOTE: A bug in CIAO 3.1 does not allow for plotting the PHA data in the channel space when the instrument model is specified.
Sets the unit type for the y-axis of a plot.
sherpa> PLOTY [#] {COUNTS | RATE || ONE | ENERGY | WAVE | ENERGY2 | WAVE2 }
where # may specify the number of the dataset; the default dataset is 1.
The command PLOTY actually controls two aspects of plot appearance: whether rates or raw data are shown; and whether the amplitudes in each bin are to be multiplied by the energy/wavelength of the bin.
| Argument: | Description: |
| ONE | No multiplication by energy or wavelength. |
| ENERGY | Multiply the amplitudes in each bin by the bin energies. |
| WAVE | Multiply the amplitudes in each bin by the bin wavelengths. |
| ENERGY2 | Multiply the amplitudes in each bin by the bin energies squared. |
| WAVE2 | Multiply the amplitudes in each bin by the bin wavelengths squared. |
The plot labeling function assumes exposure times in seconds, ARFs
with effective area information in ![]() , and
energies/wavelengths in keV/
Å.
If necessary, the user can change the label with the
ChIPS command YLABEL.
, and
energies/wavelengths in keV/
Å.
If necessary, the user can change the label with the
ChIPS command YLABEL.
Note that in CIAO 3.0, the user cannot have separate PLOTY settings for source and background datasets with the same dataset #, i.e., changing PLOTY changes the plot appearance for both the source and the background datasets.
Also note that PLOTY controls not just the appearance of 1D plots, but also the output generated by the WRITE command. This may be changed in a future version of Sherpa.
Examples:
Reset the y-axis units to counts, after they have automatically been set to rate with the definition of an instrument model:
sherpa> READ DATA data/example.pha sherpa> RSP[instrumentA](example.rmf, example.arf) The inferred file type is ARF. If this is not what you want, please specify the type explicitly in the data command. sherpa> INSTRUMENT = instrumentA sherpa> LPLOT DATA <Rate data are displayed.> sherpa> PLOTY COUNTS sherpa> LPLOT DATA <Counts data are displayed.>
Estimates confidence intervals for selected thawed parameters.
sherpa> PROJECTION [<dataset range> | ALLSETS] [ <arg_1> , ... ]
where ![]() dataset range
dataset range![]()
![]() #, or more generally #:#,#:#,...,
such that # specifies a dataset number, and #:# represents an
inclusive range of datasets; one may specify multiple inclusive ranges
by separating them with commas. The default
is to estimate limits using data from all appropriate datasets.
#, or more generally #:#,#:#,...,
such that # specifies a dataset number, and #:# represents an
inclusive range of datasets; one may specify multiple inclusive ranges
by separating them with commas. The default
is to estimate limits using data from all appropriate datasets.
The command-line arguments ![]() arg_n
arg_n![]() may be:
may be:
| Argument | Description |
|---|---|
| A specified model component parameter (e.g., GAUSS.pos). | |
| A specified model component parameter (e.g., g.pos). |
The user may configure PROJECTION via the Sherpa state object structure proj. The current values of the fields of this structure may be displayed using the command print(sherpa.proj), or using the more verbose Sherpa/S-Lang module function list_proj().
The structure fields are:
| Field | Description |
|---|---|
| fast | If 1, use a fast optimization algorithm (LEVENBERG-MARQUARDT or SIMPLEX) regardless of the current METHOD. If 0, use the current METHOD. |
| sigma | Specifies the number of |
Field values may be set using directly, e.g.,
sherpa> sherpa.proj.sigma = 2.6
NOTE: strict checking of value inputs is not done, i.e., the user can errantly change arrays to scalars, etc. To restore the default settings of the structure at any time, use the Sherpa/S-Lang module function restore_proj().
Confidence interval bounds are determined for each selected parameter in turn. A given parameter's value is varied along a grid of values while the values of all the other nominally thawed parameters are allowed to float to new best-fit values (compare to UNCERTAINTY, where the values of all the other nominally thawed parameters remain fixed to their best-fit values). This method of estimating confidence interval bounds gives truly accurate results only in special cases (see caveats below).
Because PROJECTION estimates confidence intervals for
each parameter independently, the relationship between
sigma and the change in statistic value ![]() can be particularly simple:
can be particularly simple:
![]() for statistics
sampled from the
for statistics
sampled from the ![]() distribution
and for the Cash statistic, and is approximately equal to
distribution
and for the Cash statistic, and is approximately equal to
![]() for fits based on
the general log-likelihood (
for fits based on
the general log-likelihood (
![]() ).
).
| Confidence |
|
|
|
| 68.3% | 1.0 | 1.00 | 0.50 |
| 90.0% | 1.6 | 2.71 | 1.36 |
| 95.5% | 2.0 | 4.00 | 2.00 |
| 99.0% | 2.6 | 6.63 | 3.32 |
| 99.7% | 3.0 | 9.00 | 4.50 |
One may determine if these conditions hold, for example, by plotting
the fit statistic as a function of each parameter's values (the curve
should approximate a parabola) and by examining contour plots of the
fit statistics made by varying the values of two parameters at a time
(the contours should be elliptical, and parameter space boundaries
should be no closer than approximately
![]() from the best-fit point).
The INTERVAL-PROJECTION
and
REGION-PROJECTION
commands can be used for these checks.
from the best-fit point).
The INTERVAL-PROJECTION
and
REGION-PROJECTION
commands can be used for these checks.
If either of these conditions does not hold, then the output from PROJECTION may be meaningless except to give an idea of the scale of the confidence intervals. To accurately determine the confidence intervals, one would have to reparameterize the model, or use Monte Carlo simulations or Bayesian methods.
The user may retrieve the upper- and lower-bound estimates using the Sherpa/S-Lang module function get_proj.
Examples:
List the current and default values of the proj structure, and restore the default values:
sherpa> sherpa.proj.sigma = 5 sherpa> list_proj() Parameter Current Default Description ---------------------------------------------------------------------- fast 1 1 Switch to LM/simplex: 0(n)/1(y) sigma 5 1 Number of sigma sherpa> restore_proj() sherpa> list_proj() Parameter Current Default Description ---------------------------------------------------------------------- fast 1 1 Switch to LM/simplex: 0(n)/1(y) sigma 1 1 Number of sigma
Search parameter space to find a range of parameter values, within a confidence in terval of 68.3%, for all thawed parameters:
sherpa> READ DATA example1.dat
sherpa> PARAMPROMPT OFF
Model parameter prompting is off
sherpa> SOURCE = poly[p]
sherpa> THAW p.c1 p.c2 p.c3
sherpa> METHOD SIMPLEX
sherpa> FIT
...
sherpa> PROJECTION
Projection: optimization reset to LM.
Projection complete for parameter: p.c0
Projection complete for parameter: p.c1
Projection complete for parameter: p.c2
Projection complete for parameter: p.c3
Computed for projection.sigma = 1
--------------------------------------------------------
Parameter Name Best-Fit Lower Bound Upper Bound
--------------------------------------------------------
p.c0 -0.302766 -8.34233 +7.87706
p.c1 0.598026 -8.7713 +9.42289
p.c2 0.792121 -2.72725 +2.53915
p.c3 0.018429 -0.205409 +0.2213
Changes the Sherpa prompt.
sherpa> PROMPT "<arg>"
where ![]() arg
arg![]() is the string that
will replace the current Sherpa prompt.
is the string that
will replace the current Sherpa prompt.
Examples:
Change the Sherpa prompt:
sherpa> PROMPT "hello> " hello>
Return the Sherpa prompt to the default:
hello> PROMPT "sherpa> " sherpa>
Terminates the Sherpa program.
See the BYE command.
Inputs the contents of one or more files.
sherpa> READ <arg> [# [ID]] <filespec> [,[# [ID]] <filespec>,...]
where # specifies the number of the dataset to be associated with the data file (default dataset number is 1). The ID modifier is used only when background data are input, and then if and only if the Sherpa state object variable multiback is set to 1, i.e., if more than one background dataset is to be associated with a single source dataset. The ID modifier may be any unreserved string (e.g., A, foo, etc.), i.e., a string that is not a parsable command.
![]() arg
arg![]() may be:
may be:
| Argument | To input a file containing: |
|---|---|
| {DATA |
Source |
| {ERRORS |
Estimated total errors for the source |
| {SYSERRORS |
Systematic errors for the source |
| {WEIGHT |
Statistic weight values assigned to each source |
| {FILTER |
Mask values (0 |
| {GROUP |
Grouping values (1 |
| {QUALITY |
Quality values (0 |
| MDL | A model descriptor list file. |
Sherpa currently supports the following file types:
| Containing: | |
|---|---|
| ASCII | ASCII data |
| FITS | FITS image data |
| FITSIMAGE | FITS image data |
| FITSBIN | FITS binary table data |
| IMH | IRAF image data |
| PHA | Pulse-height amplitude data |
For each of these file types, we discuss the
allowed ![]() filespec
filespec![]() arguments in turn.
arguments in turn.
where
| The name of the data file (this may also include a path). | |
| A list of column numbers. |
The modifier ASCII indicates that the input data is to be treated as unbinned (i.e., models are to be evaluated at single points), while HISTOGRAM leads Sherpa to create a binned dataset from the ASCII file. This is done by treating the first data point as the lower bin boundary for the first channel, the second data point as the upper bin boundary for the first channel and the lower bin boundary for the second channel, etc. The last data point (which has no defined upper boundary in this scheme) is dropped. This command is particularly useful when using additive XSPEC models, since these models are always integrated over a bin and so require binned data.
Note that when reading an ASCII file containing more than two columns,
only the data in the first two columns are input. To read other columns,
or more than two columns, specify the column numbers with
![]() colnumbers
colnumbers![]() . See the examples below.
. See the examples below.
Also note that the last column input is considered the dependent coordinate.
FITS, FITSIMAGE, IMH, and QP File Types:
where
| The name of the data file (this may also include a path). | |
| A filtering and/or binning command argument. See the "Using Data Model Filters" section for further information. |
If the command argument {FITS ![]() FITSIMAGE}
is not included when reading a FITS file,
Sherpa will attempt to determine the FITS file type
(e.g., 2-D FITS image vs. 1-D FITS binary table)
from the FITS header keywords.
FITSIMAGE}
is not included when reading a FITS file,
Sherpa will attempt to determine the FITS file type
(e.g., 2-D FITS image vs. 1-D FITS binary table)
from the FITS header keywords.
Note that whenever ![]() virtual_file_syntax
virtual_file_syntax![]() is
specified,
is
specified,
![]() filename
filename![]()
![]() virtual_file_syntax
virtual_file_syntax![]() usually must
be surrounded by quotes, " ".
usually must
be surrounded by quotes, " ".
FITSBIN (FITS Binary Table) File Type:
where
| The name of the data file (this may also include a path). | |
| A filtering and/or binning command argument. See the "Using Data Model Filters" section for further information. |
Note that ![]() virtual_file_syntax
virtual_file_syntax![]() should be included, in
order to specify the desired columns. Otherwise, Sherpa
will try to input data from all columns, which will lead to
an error message if there are more than two columns.
should be included, in
order to specify the desired columns. Otherwise, Sherpa
will try to input data from all columns, which will lead to
an error message if there are more than two columns.
Also note that if the command argument FITSBIN is not included, Sherpa will attempt to determine the FITS file type (e.g., 2-D FITS image vs. 1-D FITS binary table) from the FITS header keywords.
Last, note that whenever ![]() virtual_file_syntax
virtual_file_syntax![]() is
specified,
is
specified,
![]() filename
filename![]()
![]() virtual_file_syntax
virtual_file_syntax![]() usually must
be surrounded by quotes, " ".
usually must
be surrounded by quotes, " ".
PHA File Types (Types I and II):
where
| The name of the data file (this may also include a path). |
Note that if a FITS binary table is input with no
![]() filetype
filetype![]() modifier
modifier ![]() FITSBIN or
PHA
FITSBIN or
PHA![]() , the file type will be automatically inferred;
if the file contains an extension named SPECTRUM, it
is assumed to be a PHA file.
, the file type will be automatically inferred;
if the file contains an extension named SPECTRUM, it
is assumed to be a PHA file.
If the input PHA file contains a GROUPING column, the data are automatically grouped. Also, Sherpa retains the contents of the QUALITY columns, allowing the user to, e.g., filter out bad channels by issuing the command IGNORE BAD.
If the input PHA file contains a STAT_ERR column, its contents are ignored (and a message printed to the screen). If you wish to use these statistical error estimates (as opposed to letting Sherpa estimate the errors given a chosen STATISTIC, you should read them in as follows (substituting BERRORS if appropriate):
sherpa> READ ERRORS "<filename>[cols CHANNEL,STAT_ERR] FITSBIN
On the other hand, if the input PHA file contains a SYS_ERR column, its contents are used; see SYSERRORS for more information.
If the STAT_ERR is read in before a fit, and SYS_ERR was also read in, then
the error in a bin is
![]() .
.
If STAT_ERR is not read in, and SYS_ERR is read in, then the error in a bin is
![]() .
.
If the header of the input PHA file includes keywords that references background data files, or source and/or background response files, then these files and automatically read in and, if appropriate, RSP instrument models are automatically defined (See INSTRUMENT command for more information). When these files are read in, the following kinds of messages are issued:
RMF is being input from: <directory_path>/example.rmf ARF is being input from: <directory_path>/example.arf Background data are being input from: <directory_path>/example_bkg.pha Background RMF is being input from: <directory_path>/example_bkg.rmf Background ARF is being input from: <directory_path>/example_bkg.arf
Note the following, for all file types:
unix% dmcopy "infile.fits[spec 1][spec 2]" outfile.fits
you can also do
sherpa> read "infile.fits[spec 1][spec 2]"
This is especially useful when working with very large files. For example:
sherpa> read "evt.fits[bin sky=4][opt mem=100]"
bins the event file by a factor of four and allocates additional memory. A similar command (omitting the binning factor) can be used to read in an image.
Examples:
Input an ASCII data file having a .dat extension name:
sherpa> READ DATA 1 example.dat ASCII 1 2
Reads the first two columns of the ASCII data file example.dat, as dataset number 1. The following commands are each equivalent to the above command:
sherpa> READ DATA 1 example.dat ASCII sherpa> READ DATA 1 example.dat sherpa> READ DATA example.dat sherpa> DATA example.dat
Note that, if not specified, only the first two columns are read. Also, the dataset number is assumed to be 1 if it is not specified.
Input ASCII data and error files not having a .dat extension name:
sherpa> READ DATA 1 example.qdp ASCII 1 2 sherpa> READ ERRORS 1 example.qdp ASCII 1 3
The first command reads columns 1 and 2 of the ASCII data file example.qdp, as dataset number 1. Then, columns 1 and 3 of the same ASCII data file are read, as the measurement errors of this dataset. Note that using the ASCII argument is no longer necessary for input of files not having a .dat extension. Thus, the following READ DATA commands are each equivalent to the above READ command:
sherpa> READ DATA 1 example.qdp ASCII sherpa> READ DATA 1 example.qdp sherpa> READ DATA example.qdp sherpa> DATA example.qdp
Input various data columns from ASCII data and error files:
sherpa> READ DATA 1 example.dat 3 8 sherpa> READ ERRORS 1 example.dat 3 5 sherpa> READ DATA 2 example.dat sherpa> READ ERRORS 2 example.dat 1 4
The first command reads columns 3 and 8 of the ASCII data file example.dat, as dataset number 1. Next, the measurement errors for dataset 1, from columns 3 and 5 of example.dat are read. Then, the first and second columns of the ASCII data file example.dat, as dataset number 2, are read. The last command reads the measurement errors for dataset 2, from columns 1 and 4 of example.dat.
Overwrite dataset number 1:
sherpa> READ DATA 1 example1.dat 3 8 sherpa> READ DATA example2.dat
Note that the command READ DATA example2.dat overwrites the data that had been input from example1.dat.
Input multiple ASCII datasets, using a single command:
sherpa> READ DATA 1 example1.dat, 2 example2.dat, 3 example3.dat 2 3
This example illustrates the input of multiple data files simultaneously. The command reads example1.dat as dataset number 1, and example2.dat as dataset number 2. Columns 2 and 3 of example3.dat are read as dataset number 3. The following command is equivalent:
sherpa> READ DATA example1.dat, example2.dat, example3.dat 2 3
Input ASCII data, and weight assignments from a file:
sherpa> READ DATA example1.dat 1 2 sherpa> READ WEIGHT example1.dat 1 3 sherpa> SHOW WEIGHTS
The first command reads columns 1 and 2 of the ASCII data file example1.dat, as dataset number 1. Column 3 of example1.dat contains a weight assignment for each of the data points. These weight assignments are input with the second command. Current weight assignments for each data point can be reported with the command SHOW WEIGHTS.
Input ASCII data, and filter assignments from a file:
sherpa> READ DATA example1.dat 1 2 sherpa> READ FILTER example1.dat 1 3 sherpa> SHOW FILTER
The first command reads columns 1 and 2 of the ASCII data file example1.dat, as dataset number 1. Column 3 of example1.dat contains a filter assignment for each of the data points (1 for the data point to be included; 0 for the data point to be excluded). Current filter assignments for each data point can be reported with the command SHOW FILTER.
Compare input ASCII data to input HISTOGRAM data:
sherpa> READ DATA 1 data/example.dat sherpa> SHOW DATA 1 Y Column: Counts Dimensions: 1 Total Size: 4 bins (or pixels) Axis: 0; Name: Bin Length: 4 bins (or pixels) File Name: data/example.dat SubSection (if any): File Type: ASCII [1] = 1 [2] = 5 [3] = 8 [4] = 17 sherpa> READ DATA 2 data/example.dat HISTOGRAM sherpa> SHOW DATA 2 Y Column: Counts Dimensions: 1 Total Size: 3 bins (or pixels) Axis: 0; Name: Bin Length: 3 bins (or pixels) File Name: data/example.dat SubSection (if any): File Type: [1.500000] = 1 [2.500000] = 5 [3.500000] = 8
Utilize the HISTOGRAM argument to input binned data:
sherpa> READ DATA 1 data/spectrum_notintegrated.dat ASCII
The above command inputs data from an ASCII file that has two columns:
energy (in keV), and flux (in
![]() ).
Note that this
dataset cannot be used with additive XSPEC models,
since they require binned data.
).
Note that this
dataset cannot be used with additive XSPEC models,
since they require binned data.
sherpa> READ DATA 2 data/spectrum_integrated.dat HISTOGRAM
The above command inputs and bins data from an ASCII file that
has two columns:
energy (in keV), and flux (in
![]() ).
(i.e., where the second
column contains data of units
).
(i.e., where the second
column contains data of units
![]() multiplied by the bin width in keV).
Note that this dataset can be used with XSPEC models, since
the input data are binned.
multiplied by the bin width in keV).
Note that this dataset can be used with XSPEC models, since
the input data are binned.
Input a 2-D FITS image data file:
sherpa> READ DATA 1 example_img.fits FITS
This command reads the 2-D FITS image example_img.fits as dataset number 1. The following command is equivalent:
sherpa> READ DATA 1 example_img.fits FITSIMAGE
The following commands are also equivalent to the above, if the example_img.fits file contains the proper header kewords identifying the file as a 2-D FITS image:
sherpa> READ DATA example_img.fits sherpa> DATA example_img.fits
Input 2-D FITS image data and background files:
sherpa> READ DATA 3 example_img.fits FITSIMAGE sherpa> READ BACK 3 example_img_bkg.fits FITSIMAGE
First, the FITS image example_img.fits, as dataset number 3, is read. Then, the background FITS image for this dataset is read. Note that the command SUBTRACT must be issued in order to actually have the background subtracted from the data.
Input a portion of a 2-D FITS image data file:
sherpa> READ DATA "example_img.fits[#1=100:200, #2=100:400]" FITS
This command reads the specified portion of the 2-D FITS image example_img.fits. Note that, by default, the data is taken from the first FITS block for which NAXIS is nonzero. The following command is equivalent:
sherpa> READ DATA "example_img.fits[100:200,100:400]" FITS
Input various data columns from a FITS binary data file:
sherpa> READ DATA 1 "example_bin.fits[2][columns #1, #2]" FITSBIN
This command reads the first two columns from the second extension of the FITS binary table file example_bin.fits, as dataset number 1. Note that column numbers or names must always be specified when reading FITS binary table files. The following commands are each equivalent to the above command:
sherpa> READ DATA 1 "example_bin.fits[2][cols #1, #2]" FITSBIN sherpa> DATA "example_bin.fits[2][cols #1, #2]" FITSBIN
Input various data columns from FITS binary data files:
sherpa> READ DATA 2 "example_bin.fits[2][cols TIME, EXPNO]" FITSBIN sherpa> READ DATA 3 "example_bin.fits[EVENTS][cols time, expno]" FITSBIN
The first command reads columns time and expno, from the second extension of the FITS binary table file example_bin.fits, as dataset number 2. The second command reads columns time and expno, from the EVENTS extension of the FITS binary table file example_bin.fits, as dataset number 3. Note that columns may be specified by case insensitive name. Also, the FITS extension can be specified by either the number or the name of the extension (in this example, the name of the second extension is EVENTS).
Input a 2-D image by binning columns from a FITS binary data file:
sherpa> DATA "example_bin.fits[bin chipx, chipy]" FITSIMAGE Warning: Could not retrieve WCS coord descriptor
This command inputs into Sherpa the FITS binary table example_bin.fits, but bins the table to create an image using the chipx and chipy columns. Note that the FITSIMAGE argument is required since it is ultimately a FITS image that is being input to Sherpa.
Input a 2-D image by binning and filtering columns from a FITS binary data file:
sherpa> DATA "example_bin.fits[bin chipx=200:400:4, chipy=300:400:4]" FITSIMAGE
This command creates and inputs into Sherpa, an image using the chipx and chipy columns of the binary FITS table file example_bin.fits. In this example, ranges for the axes, and bin sizes, are given. Note that the FITSIMAGE argument is required.
Input a 2-D image data file:
sherpa> READ DATA 1 example.imh IMH
This command reads the image example.imh, as dataset number 1. The following commands are each equivalent:
sherpa> READ DATA example.imh IMH sherpa> READ DATA example.imh sherpa> DATA example.imh
Input a portion of a 2-D image data file:
sherpa> READ DATA 2 "example.imh[#1=100:200, #2=100:400]"
This command reads a portion of the image example.imh, from Axis 0 coordinates 100 to 200 and from Axis 1 coordinates 100 to 400. The data are read as dataset number 2. The following command is equivalent:
sherpa> READ DATA 2 "example.imh[100:200, 100:400]"
Input PHA data and background files:
sherpa> READ DATA 4 example.pha PHA The inferred file type is PHA. If this is not what you want, please specify the type explicitly in the data command. WARNING: using systematic errors specified in the PHA file. RMF is being input from: <directory_path>/example2.rmf ARF is being input from: <directory_path>/example2.arf Background data are being input from: <directory_path>/example2_bkg.pha sherpa> READ BACK 4 example_bkg.pha The inferred file type is PHA. If this is not what you want, please specify the type explicitly in the data command.
First, the PHA data file example.pha is read as dataset number 4. Note that the systematic errors contained in the PHA data file are input. These input systematic errors are added in quadrature with the statistical errors (which are automatically computed using the currently defined STATISTIC). Note also that since the header of the PHA data file contains the proper keywords, instrument and background data files are automatically loaded. The READ BACK 4 example_bkg.pha command inputs the background PHA file is read for dataset number 4.
Input multiple PHA data files:
sherpa> READ DATA example1.pha PHA, example2.pha The inferred file type is PHA. If this is not what you want, please specify the type explicitly in the data command. WARNING: using systematic errors specified in the PHA file. The inferred file type is PHA. If this is not what you want, please specify the type explicitly in the data command. WARNING: using systematic errors specified in the PHA file.
This example illustrates the input of multiple data files simultaneously. The command reads example1.dat as dataset number 1, and example2.dat as dataset number 2. Again, note that the statistical errors in the PHA data files are not input, but the systematic errors are input.
Controls output of parameters values and statistics to an ASCII file.
sherpa> RECORD [{ON | OFF}]
During every iteration of a fit, points in parameter space are chosen and statistics computed. The user can access information about these intermediate fits by issuing the command RECORD ON and retrieving the contents of the file described below. RECORD OFF turns off the recording. Issuing the command RECORD alone causes Sherpa to display the current setting.
Fit information is written to the ASCII file
search-![]() username
username![]() .dat, located
the $ASCDS_WORK_PATH directory; type "echo
$ASCDS_WORK_PATH" to find the location on your system.
.dat, located
the $ASCDS_WORK_PATH directory; type "echo
$ASCDS_WORK_PATH" to find the location on your system.
Note that successive FIT commands cause the file contents to be overwritten!
The fit information may also be accessed via the Sherpa/S-Lang module function get_record.
Examples:
Write fit parameter values and statistics to an ASCII file:
sherpa> PARAMPROMPT OFF
Model parameter prompting is off
sherpa> DATA data/example1.dat
sherpa> POLYNOM1D[my]
sherpa> THAW my.c1 my.c2
sherpa> SOURCE 1 = my
sherpa> METHOD SIMPLEX
sherpa> RECORD ON
sherpa> FIT
smplx: v1.3
smplx: initial statistic value = 3.25453E+02
smplx: converged to minimum = 3.44058E-01 at iteration = 82
smplx: final statistic value = 3.44058E-01
my.c0 -0.996019
my.c1 0.672607
my.c2 0.923389
sherpa> $echo $ASCDS_WORK_PATH
/tmp
sherpa> $ls /tmp/search*
/tmp/search-<username>dat
sherpa> $more /tmp/search-<username>.dat
my.c0 my.c1 my.c2 Chi-Squared
33 0 0 325.453
33 0 0 325.453
32.34 0.01 0.01 312.682
32.34 0.01 0.01 312.682
31.9 0.00666667 0.00333333 303.974
...
Creates a contour plot of confidence regions using the PROJECTION algorithm. The commands REG-PROJ and REGPROJ are abbreviated equivalents.
sherpa> REGION-PROJECTION [<dataset range> | ALLSETS] <arg_1> <arg_2>
where ![]() dataset range
dataset range![]()
![]() #, or more generally #:#,#:#,...,
such that # specifies a dataset number, and #:# represents an
inclusive range of datasets; one may specify multiple inclusive ranges
by separating them with commas. The default
is to compute contours using data from all appropriate datasets.
#, or more generally #:#,#:#,...,
such that # specifies a dataset number, and #:# represents an
inclusive range of datasets; one may specify multiple inclusive ranges
by separating them with commas. The default
is to compute contours using data from all appropriate datasets.
The two command-line arguments may be:
| Argument | Description |
|---|---|
| A specified model component parameter (e.g., GAUSS.pos). | |
| A specified model component parameter (e.g., g.pos). |
The user may configure REGION-PROJECTION via the Sherpa state object structure regproj. The current values of the fields of this structure may be displayed using the command print(sherpa.regproj), or using the more verbose Sherpa/S-Lang module function list_regproj().
The structure fields are:
| Field | Description |
|---|---|
| fast | If 1, use a fast optimization algorithm (LEVENBERG-MARQUARDT or SIMPLEX) regardless of the current METHOD. If 0, use the current METHOD. |
| expfac | A multiplicative factor that expands the grid limits estimated by the COVARIANCE algorithm, if the grid limits are determined automatically (see arange, and below). |
| arange | If 1, the grid limits are to be determined automatically. If 0, the grid limits are specified (see min and max). |
| min | An array of length two giving the grid minima for each plot axis.
These are always linear quantities, regardless of the setting of
log (see below).
The array is ignored if arange |
| max | An array of length two giving the grid maxima for each plot axis.
These are always linear quantities, regardless of the setting of
log (see below).
The array is ignored if arange |
| log | An array of length two specifying whether to use linear (0) or logarithmic (1) spacing of grid points along each plot axis. |
| nloop | An array of length two specifying the number of grid points along each plot axis. |
| sigma | An array of arbitrary length specifying the number of
|
Field values may be set using directly. If the field does not contain an array, e.g.,
sherpa> sherpa.regproj.arange = 0
and if it does contain an array, e.g.,
sherpa> sherpa.regproj.nloop = [25,20]
NOTE: strict checking of value inputs is not done, i.e., the user can errantly change arrays to scalars, etc. To restore the default settings of the structure at any time, use the Sherpa/S-Lang module function restore_regproj().
The confidence regions are determined by varying each selected
parameter's value on the determined (arange ![]() 1) or
specified (arange
1) or
specified (arange ![]() 0)
grid, computing the best-fit statistic at each grid point, and
interpolating on the grid. REGION-PROJECTION differs from
REGION-UNCERTAINTY in
that all other thawed parameters are allowed to float to new best-fit
values, instead of being fixed to their best-fit values. This makes
REGION-PROJECTION contours more accurate, but causes
their computation to proceed more slowly. For a fuller theoretical
description of error estimation, see PROJECTION, UNCERTAINTY, and COVARIANCE.
0)
grid, computing the best-fit statistic at each grid point, and
interpolating on the grid. REGION-PROJECTION differs from
REGION-UNCERTAINTY in
that all other thawed parameters are allowed to float to new best-fit
values, instead of being fixed to their best-fit values. This makes
REGION-PROJECTION contours more accurate, but causes
their computation to proceed more slowly. For a fuller theoretical
description of error estimation, see PROJECTION, UNCERTAINTY, and COVARIANCE.
If arange ![]() 1, then the grid limits for
the plot are determined automatically. For increased speed, the grid
limits are determined using the error estimates from
COVARIANCE. The covariance errors
are computed assuming a change in fit statistic from the best-fit
value of
1, then the grid limits for
the plot are determined automatically. For increased speed, the grid
limits are determined using the error estimates from
COVARIANCE. The covariance errors
are computed assuming a change in fit statistic from the best-fit
value of ![]() , which is a function of
the largest value of sigma
(e.g.,
, which is a function of
the largest value of sigma
(e.g.,
![]() if the statistic is
if the statistic is ![]() and
3 is the largest element of the array sigma.
The covariance errors are then multiplied by
expfac and are subtracted
from and added to the best-fit parameter values to determine the
lower and upper grid limits.
and
3 is the largest element of the array sigma.
The covariance errors are then multiplied by
expfac and are subtracted
from and added to the best-fit parameter values to determine the
lower and upper grid limits.
Note that the output of COVARIANCE may be adversely affected if the problem is not well-posed (since a matrix inversion is involved in the error calculation), or if the fit did not reach its local minimum. If the plot does not appear correct, consider running COVARIANCE to check the errors, and/or setting the plot limits manually.
For increased speed, the best fit at each grid point is calculated
using the LEVENBERG-MARQUARDT
optimization method if fast ![]() 1 and
a
1 and
a ![]() statistic is used to fit;
the user's chosen optimization method is
then reset after the plot is shown.
(If fast
statistic is used to fit;
the user's chosen optimization method is
then reset after the plot is shown.
(If fast ![]() 1 and a non-
1 and a non-![]() statistic is used during fitting, then the
SIMPLEX
method is used instead.)
statistic is used during fitting, then the
SIMPLEX
method is used instead.)
The grid-point values and best-fit statistics at each grid point may be retrieved using the Sherpa/S-Lang module function get_regproj. See the examples below.
Examples:
List the current and default values of the regproj structure, and restore the default values:
sherpa> sherpa.regproj.arange = 0 sherpa> sherpa.regproj.log = [1,1] sherpa> sherpa.regproj.sigma = [1,3,5] sherpa> list_regproj() Parameter Current Default Description ---------------------------------------------------------------------- fast 1 1 Switch to LM/simplex: 0(n)/1(y) expfac 3 3 Expansion factor for grid arange 0 1 Auto-range: 0(n)/1(y) min [0,0] [0,0] Minimum values, each axis max [0,0] [0,0] Maximum values, each axis log [1,1] [0,0] Log-spacing: 0(n)/1(y), each axis nloop [10,10] [10,10] Number of grid points, each axis sigma [1,3,5] [1,2,3] Number of sigma, each contour sherpa> restore_regproj() sherpa> list_regproj() Parameter Current Default Description ---------------------------------------------------------------------- fast 1 1 Switch to LM/simplex: 0(n)/1(y) expfac 3 3 Expansion factor for grid arange 1 1 Auto-range: 0(n)/1(y) min [0,0] [0,0] Minimum values, each axis max [0,0] [0,0] Maximum values, each axis log [0,0] [0,0] Log-spacing: 0(n)/1(y), each axis nloop [10,10] [10,10] Number of grid points, each axis sigma [1,2,3] [1,2,3] Number of sigma, each contour
Determine
![]() confidence
regions for a fit:
confidence
regions for a fit:
sherpa> READ DATA example1.dat
sherpa> PARAMPROMPT OFF
sherpa> SOURCE = POLYNOM1D[my]
sherpa> THAW my.c1 my.c2
sherpa> my.c0.min = -10
sherpa> FIT
...
sherpa> sherpa.regproj.sigma = [1,2]
sherpa> sherpa.regproj.expfac = 4
sherpa> REGION-PROJECTION my.c0 my.c2
Region-Projection: computing grid size with covariance...done.
outer grid loop 20% done...
outer grid loop 40% done...
outer grid loop 60% done...
outer grid loop 80% done...
Minimum: 0.255419
Levels are: 2.55142 6.43642
...
Determine
![]() confidence regions
for a fit using manually set grid limits:
confidence regions
for a fit using manually set grid limits:
sherpa> sherpa.regproj.arange = 0
sherpa> sherpa.regproj.min = [-15,0]
sherpa> sherpa.regproj.max = [15,2]
sherpa> REGION-PROJECTION my.c0 my.c2
Region-Projection: grid size set by user.
outer grid loop 20% done...
outer grid loop 40% done...
outer grid loop 60% done...
outer grid loop 80% done...
Minimum: 0.255419
Levels are: 2.55142 6.43642
Save the results of REGION-PROJECTION to an ASCII file:
[...run REGION-PROJECTION...]
sherpa> my_var = get_regproj()
sherpa> writeascii("my_output.dat",my_var.x0,my_var.x1,my_var.y)
sherpa> quit
Goodbye.
unix> more my_output.dat
-15 0 12.8958
-15 0.222222 14.7571
-15 0.444444 18.5405
...
Creates a contour plot of confidence regions using the UNCERTAINTY algorithm. The commands REG-UNC and REGUNC are abbreviated equivalents.
sherpa> REGION-UNCERTAINTY [<dataset range> | ALLSETS] <arg_1> <arg_2>
where ![]() dataset range
dataset range![]()
![]() #, or more generally #:#,#:#,...,
such that # specifies a dataset number, and #:# represents an
inclusive range of datasets; one may specify multiple inclusive ranges
by separating them with commas. The default
is to compute contours using data from all appropriate datasets.
#, or more generally #:#,#:#,...,
such that # specifies a dataset number, and #:# represents an
inclusive range of datasets; one may specify multiple inclusive ranges
by separating them with commas. The default
is to compute contours using data from all appropriate datasets.
The two command-line arguments may be:
| Argument | Description |
|---|---|
| A specified model component parameter (e.g., GAUSS.pos). | |
| A specified model component parameter (e.g., g.pos). |
The user may configure REGION-UNCERTAINTY via the Sherpa state object structure regunc. The current values of the fields of this structure may be displayed using the command print(sherpa.regunc), or using the more verbose Sherpa/S-Lang module function list_regunc().
The structure fields are:
| Field | Description |
|---|---|
| expfac | A multiplicative factor that expands the grid limits estimated by the UNCERTAINTY algorithm, if the grid limits are determined automatically (see arange, and below). |
| arange | If 1, the grid limits are to be determined automatically. If 0, the grid limits are specified (see min and max). |
| min | An array of length two giving the grid minima for each plot axis.
These are always linear quantities, regardless of the setting of
log (see below).
The array is ignored if arange |
| max | An array of length two giving the grid maxima for each plot axis.
These are always linear quantities, regardless of the setting of
log (see below).
The array is ignored if arange |
| log | An array of length two specifying whether to use linear (0) or logarithmic (1) spacing of grid points along each plot axis. |
| nloop | An array of length two specifying the number of grid points along each plot axis. |
| sigma | An array of arbitrary length specifying the number of
|
Field values may be set using directly. If the field does not contain an array, e.g.,
sherpa> sherpa.regunc.arange = 0
and if it does contain an array, e.g.,
sherpa> sherpa.regunc.nloop = [25,20]
NOTE: strict checking of value inputs is not done, i.e., the user can errantly change arrays to scalars, etc. To restore the default settings of the structure at any time, use the Sherpa/S-Lang module function restore_regunc().
The confidence regions are determined by varying each selected parameter's value along an automatically determined grid, computing the best-fit statistic at each grid point and interpolating. REGION-UNCERTAINTY differs from REGION-PROJECTION in that all other thawed parameters are fixed to their best-fit values, rather than being allowed to float to new best-fit values. This makes REGION-UNCERTAINTY contours less accurate, but causes them to be computed much more quickly. For a fuller theoretical description of error estimation, see PROJECTION, UNCERTAINTY, and COVARIANCE.
The grid limits for the plot are determined automatically using the
UNCERTAINTY algorithm. Each
parameter's value is varied until the fit statistic is increased by
![]() , which is a function of the
largest value of sigma (e.g.,
, which is a function of the
largest value of sigma (e.g.,
![]() if the statistic is
if the statistic is
![]() and
3 is the largest element of the array sigma.
The uncertainty errors are then multiplied by
expfac and are subtracted
from and added to the best-fit parameter values to determine the
lower and upper grid limits.
and
3 is the largest element of the array sigma.
The uncertainty errors are then multiplied by
expfac and are subtracted
from and added to the best-fit parameter values to determine the
lower and upper grid limits.
The grid-point values and best-fit statistics at each grid point may be retrieved using the Sherpa/S-Lang module function get_regproj. See the examples below.
Examples:
List the current and default values of the regunc structure, and restore the default values:
sherpa> sherpa.regunc.arange = 0 sherpa> sherpa.regunc.log = [1,1] sherpa> sherpa.regunc.sigma = [1,3,5] sherpa> list_regunc() Parameter Current Default Description ---------------------------------------------------------------------- expfac 3 3 Expansion factor for grid arange 0 1 Auto-range: 0(n)/1(y) min [0,0] [0,0] Minimum values, each axis max [0,0] [0,0] Maximum values, each axis log [1,1] [0,0] Log-spacing: 0(n)/1(y), each axis nloop [40,40] [40,40] Number of grid points, each axis sigma [1,3,5] [1,2,3] Number of sigma, each contour sherpa> restore_regunc() sherpa> list_regunc() Parameter Current Default Description ---------------------------------------------------------------------- expfac 3 3 Expansion factor for grid arange 1 1 Auto-range: 0(n)/1(y) min [0,0] [0,0] Minimum values, each axis max [0,0] [0,0] Maximum values, each axis log [0,0] [0,0] Log-spacing: 0(n)/1(y), each axis nloop [40,40] [40,40] Number of grid points, each axis sigma [1,2,3] [1,2,3] Number of sigma, each contour
Determine
![]() confidence regions for a fit:
confidence regions for a fit:
sherpa> READ DATA example1.dat
sherpa> PARAMPROMPT OFF
sherpa> SOURCE = POLYNOM1D[my]
sherpa> THAW my.c1 my.c2
sherpa> my.c0.min = -15
sherpa> FIT
...
sherpa> sherpa.regunc.sigma = [1,2,3,4]
sherpa> REGION-UNCERTAINTY my.c0 my.c2
Region-Uncertainty: computing grid size...done.
outer grid loop 20% done...
outer grid loop 40% done...
outer grid loop 60% done...
outer grid loop 80% done...
Minimum: 0.255419
Levels are: 2.55142 6.43642 12.0854 19.5904
Determine
![]() confidence regions for the same data:
confidence regions for the same data:
sherpa> sherpa.regunc.sigma = [1,3]
sherpa> REGION-UNCERTAINTY my.c0 my.c2
Region-Uncertainty: computing grid size...done.
outer grid loop 20% done...
outer grid loop 40% done...
outer grid loop 60% done...
outer grid loop 80% done...
Minimum: 0.255419
Levels are: 2.55142 12.0854
Save the results of REGION-UNCERTAINTY to an ASCII file:
[...run REGION-UNCERTAINTY...]
sherpa> my_var = get_regunc()
sherpa> writeascii("my_output.dat",my_var.x0,my_var.x1,my_var.y)
sherpa> quit
Goodbye.
unix> more my_output.dat
-12.7129 -0.154565 418.014
-12.7129 -0.0945145 390.736
-12.7129 -0.0344636 364.511
...
Changes the name that has been given to a model component by the user.
sherpa> RENAME <modelname> <new_modelname>
where ![]() modelname
modelname![]() is the name that has been given
to a model component by the user, and
is the name that has been given
to a model component by the user, and ![]() new_modelname
new_modelname![]() is the new name to be assigned.
is the new name to be assigned.
Examples:
Change the name of a model component:
sherpa> PARAMPROMPT OFF
sherpa> GAUSS[modelb]
sherpa> RENAME modelb modelB
sherpa> SHOW modelB
gauss1d[modelB]
Param Type Value Min Max Units
----- ---- ----- --- --- -----
1 fwhm thawed 10.0000 1.1755e-38 3.4028e+38
2 pos thawed 0.0000-3.4028e+38 3.4028e+38
3 ampl thawed 1.0000-3.4028e+38 3.4028e+38
Restores settings and/or parameter values.
sherpa> RESET [<arg>]
![]() arg
arg![]() may be:
may be:
| Argument | Description |
|---|---|
| none | Equivalent to RESET MODELS |
| ALL | Equivalent to issuing RESET MODELS and RESET METHOD |
| MODELS | Restores the parameter values of all current model components to their latest user-defined (or GUESS command-defined) values. |
| Restores the parameter values of all components of the
specified model stack (SOURCE, BACKGROUND,
PILEUP, |
|
| Restores the parameter values of the specified model component to their latest user-defined (or GUESS command-defined) values. | |
| Restores the parameter values of the specified model component to their latest user-defined (or GUESS command-defined) values. | |
| METHOD | Restores the parameter values of the current optimization method to their initial default values. |
| Restores the parameter values of the specified optimization method to their initial default values. | |
| Removes user-defined source or background data error values. Note that if the errors are not redefined, then they are subsequently computed using the current choice of statistic. # is a dataset number (default 1); see BERRORS for an explanation of ID. | |
| Resets the systematic error for every source or background data point to 0. # is a dataset number (default 1); see BSYSERRORS for an explanation of ID. | |
| FILTER |
Clears user-defined filters. # is a dataset number (default 1). NOTE: the implementation of this command in CIAO 3.0 contains a bug, such that sometimes the source and background filters are reset, and sometime only one or the other; also, there is no RESET BFILTER. |
| Resets the statistical weight assignment for every source or background data point to 1. Removes user-defined source or background statistic weight settings. # is a dataset number (default 1); see READ BWEIGHTS for an explanation of ID. |
ERASE is a related command that may be used to remove all user inputs and user-defined settings, or to remove a model component from the current Sherpa session.
Examples:
Restore the parameter values of the current method to the initial values:
sherpa> METHOD GRID
sherpa> SHOW METHOD
Optimization Method: Grid
Name Value Min Max Description
---- ----- --- --- -----------
1 totdim 4 1 24 Number of free parameters
2 nloop01 10 1 1e+07 Number of grid points
3 nloop02 10 1 1e+07 Number of grid points
4 nloop03 10 1 1e+07 Number of grid points
5 nloop04 10 1 1e+07 Number of grid points
sherpa> GRID.nloop01 = 2000
sherpa> SHOW METHOD
Optimization Method: Grid
Name Value Min Max Description
---- ----- --- --- -----------
1 totdim 4 1 24 Number of free parameters
2 nloop01 2000 1 1e+07 Number of grid points
3 nloop02 10 1 1e+07 Number of grid points
4 nloop03 10 1 1e+07 Number of grid points
5 nloop04 10 1 1e+07 Number of grid points
sherpa> RESET METHOD
sherpa> SHOW METHOD
Optimization Method: Grid
Name Value Min Max Description
---- ----- --- --- -----------
1 totdim 4 1 24 Number of free parameters
2 nloop01 10 1 1e+07 Number of grid points
3 nloop02 10 1 1e+07 Number of grid points
4 nloop03 10 1 1e+07 Number of grid points
5 nloop04 10 1 1e+07 Number of grid points
Restore the parameter values, of the current model components, to the latest user-defined values:
sherpa> DATA example.dat
sherpa> PARAMPROMPT OFF
Model parameter prompting is off
sherpa> GAUSS[modelb]
sherpa> SOURCE 1 = modelb
sherpa> modelb.pos = 1.0
sherpa> SHOW modelb
gauss1d[modelb] (integration: on)
Param Type Value Min Max Units
----- ---- ----- --- --- -----
1 fwhm thawed 2.0185 0.0202 201.8513
2 pos thawed 1 1 4
3 ampl thawed 17 0.1700 1700
sherpa> FIT
sherpa> SHOW modelb
gauss1d[modelb] (integration: on)
Param Type Value Min Max Units
----- ---- ----- --- --- -----
1 fwhm thawed 3.3671 0.0202 201.8513
2 pos thawed 4 1 4
3 ampl thawed 10.1912 0.1700 1700
sherpa> RESET modelb
sherpa> SHOW modelb
gauss1d[modelb] (integration: on)
Param Type Value Min Max Units
----- ---- ----- --- --- -----
1 fwhm thawed 2.0185 0.0202 201.8513
2 pos thawed 1 1 4
3 ampl thawed 17 0.1700 1700
Defines the instrument model to be used.
See the INSTRUMENT command for information and examples.
Initiates fitting.
See the FIT command for further information.
Saves information to an ASCII file.
sherpa> SAVE <arg> <filename>
![]() arg
arg![]() may be:
may be:
| Argument | Description |
|---|---|
| ALL | Equivalent to issuing the commands SAVE BACKGROUND, SAVE INSTRUMENT, SAVE METHOD, SAVE SYSTEM, SAVE SOURCE, and SAVE STATISTIC commands, in addition to saving the information needed to fully restore a Sherpa session, such as the names of the loaded datasets, and the currently defined filters. |
| SYSTEM | Saves the parameter values and ranges for all current source, background, and instrument model components. |
| MODELS | Saves current model component names (e.g., g for
the definition GAUSS |
| Saves current names for all model components of the
specified model stack (SOURCE, BACKGROUND,
PILEUP, |
|
| Saves current names for all model components of the specified user-defined model stack. | |
| Saves the parameter values and ranges for the specified source, background, or instrument model component. | |
| Saves the parameter values and ranges for the specified source, background, or instrument model component. | |
| METHOD | Saves the current parameter values of the selected optimization method. |
| Saves the current parameter values of the specified optimization method. | |
| STATISTIC | Saves the name of the current statistic. |
The SAVE command may be issued at any time.
Each time the command is issued the specified ASCII file
![]() filename
filename![]() is written, saving the specified
settings and values. If the specified ASCII file
already exists, it will be overwritten.
is written, saving the specified
settings and values. If the specified ASCII file
already exists, it will be overwritten.
Tip: the command SAVE ALL ![]() filename
filename![]() is useful for saving the current state
of the user's Sherpa session; the current session may
be restored at a later time by
using
is useful for saving the current state
of the user's Sherpa session; the current session may
be restored at a later time by
using ![]() filename
filename![]() as a Sherpa script.
as a Sherpa script.
Examples:
Write all settings, definitions, filters, and parameter values to an ASCII file:
sherpa> DATA data/example.pha The inferred file type is PHA. If this is not what you want, please specify the type explicitly in the data command. WARNING: using systematic errors specified in the PHA file. RMF is being input from: <directory_path>/example.rmf ARF is being input from: <directory_path>/example.arf Background data are being input from: <directory_path>/example_bkg.pha sherpa> LPLOT DATA sherpa> IGNORE ALL sherpa> NOTICE PLOT sherpa> BBODY[modelh] modelh.space parameter value [0] modelh.kT parameter value [0.592333] modelh.ampl parameter value [0.000464907] sherpa> SOURCE = modelh sherpa> SAVE ALL mysession1.shp sherpa> EXIT Goodbye.
In this example, the ASCII file named mysession1.shp is written with: all program settings; all parameter values for the current method; all parameter values, including ranges and delta settings, for the current model components; source definitions for all datasets; and the name of the current statistic. Note that information about an interactively-specified filter is also included.
Restore a session using the results of a previous SAVE ALL command:
sherpa> USE mysession1.shp
The command USE mysession1.shp restores the example session above, using the file mysession1.shp.
Write all parameter values to an ASCII file:
sherpa> SAVE modelh mymodelh.shp sherpa> $more mymodelh.shp modelh integrate on modelh.space.min = 0 modelh.space.max = 1 modelh.space.value = 0 modelh.space.type = freeze modelh.kT.min = 0.00592333 modelh.kT.max = 59.2333 modelh.kT.value = 0.592333 modelh.kT.type = thaw modelh.ampl.min = 4.64907e-06 modelh.ampl.max = 0.0464907 modelh.ampl.value = 0.000464907 modelh.ampl.type = thaw
In this example, the ASCII file named mymodelh.shp is written with the parameter values, including parameter ranges, for modelh.
Specifies the optimization method.
See the
METHOD command for the
![]() sherpa_methodname
sherpa_methodname![]() definition and examples.
definition and examples.
Sets attributes of a background dataset.
sherpa> SETBACK [# [ID]] <arg> = <numeric>
where # specifies the number of the background dataset (default dataset number is 1). The ID modifier is used if and only if the Sherpa state object variable multiback is set to 1, i.e., if more than one background dataset is to be associated with a single source dataset. The ID modifier may be any unreserved string (e.g., A, foo, etc.), i.e., a string that is not a parsable command.
The argument ![]() arg
arg![]() is one of the following options:
is one of the following options:
| Argument | Description |
|---|---|
| BACKSCALE | A normalizing quantity which can indicate the the ratio of the area of the background extraction region in an image to the full image area. |
| TIME | The exposure time of the background observation. |
The primary use of this command is to set the attributes of non-PHA datasets (e.g., ASCII datasets). Setting TIME affects the normalization of the background model, which is entered with the BACKGROUND command.
Setting BACKSCAL affects the relative normalization
of the background model when it is applied to a source region.
For instance, if the background model amplitude in a background dataset bin is
![]() , the BACKSCAL of that dataset is
, the BACKSCAL of that dataset is
![]() , and the BACKSCAL of the source dataset
is
, and the BACKSCAL of the source dataset
is ![]() , then the contribution of the background to the
source region spectrum is
, then the contribution of the background to the
source region spectrum is
 |
(1.4) |
For related information, see SETDATA.
Sets attributes of a source dataset.
sherpa> SETDATA [#] <arg> = <numeric>
where # specifies the number of the background dataset (default dataset number is 1).
The argument ![]() arg
arg![]() is one of the following options:
is one of the following options:
| Argument | Description |
|---|---|
| BACKSCALE | A normalizing quantity which can indicate the the ratio of the area of the source extraction region in an image to the full image area. |
| TIME | The exposure time of the source observation. |
The primary use of this command is to set the attributes of non-PHA datasets (e.g. ASCII datasets). Setting TIME affects the normalization of the source model, which is entered with the SOURCE command.
Setting BACKSCAL affects the relative normalization
of the background model when it is applied to a source region.
For instance, if the background model amplitude in a background dataset bin is
![]() , the BACKSCAL of that dataset is
, the BACKSCAL of that dataset is
![]() , and the BACKSCAL of the source dataset
is
, and the BACKSCAL of the source dataset
is ![]() , then the contribution of the background to the
source region spectrum is
, then the contribution of the background to the
source region spectrum is
|
(1.5) |
For related information, see SETBACK.
Examples:
Set the time of an input ASCII dataset:
sherpa> READ DATA example1.dat
sherpa> PARAMPROMPT OFF
sherpa> SOURCE = POLY[p]
sherpa> THAW p.c1 p.c2
sherpa> FIT
LVMQT: V2.0
LVMQT: initial statistic value = 325.453
LVMQT: final statistic value = 0.255412 at iteration 2
p.c0 0.305218
p.c1 -0.142263
p.c2 1.01643
sherpa> SETDATA TIME = 100
sherpa> FIT
LVMQT: V2.0
LVMQT: initial statistic value = 1.43934e+06
LVMQT: final statistic value = 0.255412 at iteration 3
p.c0 0.00292297
p.c1 -0.00133705
p.c2 0.0101542
Set the times and backscales for an input dataset with mean amplitude 60 counts and a background dataset with mean amplitude 20 counts:
sherpa> DATA spec.dat
sherpa> BACK back.dat
sherpa> PARAMPROMPT OFF
sherpa> SOURCE = CONST[co]
sherpa> BG = CONST[bo]
sherpa> FIT
LVMQT: V2.0
LVMQT: initial statistic value = 980.167
LVMQT: final statistic value = 142.424 at iteration 3
co.c0 39.3331
bo.c0 18.4647
sherpa> SETDATA TIME = 10
sherpa> SETDATA BACKSCALE = .1
sherpa> SETBACK TIME = 100
sherpa> SETBACK BACKSCALE = .25
sherpa> bo.c0.min = 0
sherpa> FIT
LVMQT: V2.0
LVMQT: initial statistic value = 7.34745e+07
LVMQT: final statistic value = 142.424 at iteration 3
co.c0 5.70591
bo.c0 0.0738588
Reports current status.
sherpa> SHOW [<arg>]
![]() arg
arg![]() may be:
may be:
| Argument | Performs the following: |
|---|---|
| Reports all current settings and parameter values. The commands SHOW and SHOW ALL are equivalent. | |
| VERBOSE | Reports all current settings and parameter values, in verbose mode. |
| MODELS | Displays information about all current model stacks and model component parameter values. |
| Displays the parameter values of all components of the
specified model stack (SOURCE, BACKGROUND,
PILEUP, |
|
| Displays the parameter values of all model components of the specified user-defined model stack. | |
| Displays the parameter values of the specified model component. | |
| Displays the parameter values of the specified model component. | |
| Lists the specified quantity; this includes everything that can be plotted/imaged with Sherpa except fits, unconvolved data/fits, unconvolved model amplitudes, and model stacks. See, e.g., documentation on the command LPLOT. (This option of SHOW may be deprecated in future versions of Sherpa since it largely duplicates the WRITE command. | |
| METHOD | Displays the name of the current optimization method, and lists parameter values. |
| Displays the name of the specified optimization method, and lists parameter values. | |
| STATISTIC | Displays the name of the current statistic. |
| FAKEIT | Displays the exposure time and backscale to be used for FAKEIT. |
| PILEUP | Reports on the pileup fractions from the most recent fit. See PILEUP for more details. |
Note: The behavior of the SHOW command is controlled by the environment variable $PAGER. The default setting for this variable should be:
unix% echo $PAGER /bin/more
This setting causes the results of the SHOW command to scroll down the screen. However, the user may prefer to use:
unix% setenv PAGER "/bin/less -s" unix% echo $PAGER /bin/less -s
Note: The SHOW command can generate more than one screen of information, particularly after data have been read, filters and models defined, models fit to the data, and statistics generated. A : symbol indicates additional information is on the next screen; tapping the space bar moves the pointer to the next screen. The end of SHOW output is indicated by END; tapping q quits the SHOW interface. (However, there are many more options at this point, including saving the screen output to a file. Tapping h (for help) will cause information on these options to be displayed.
Note: The commands SHOW MODELS,
SHOW ![]() modelname
modelname![]() , and SHOW SOURCE
currently do not return information about model parameter delta
settings. Information about model parameter delta settings
is included when using SAVE.
, and SHOW SOURCE
currently do not return information about model parameter delta
settings. Information about model parameter delta settings
is included when using SAVE.
Examples:
Report all current settings:
sherpa> SHOW Optimization Method: Levenberg-Marquardt Statistic: Chi-Squared Gehrels
This example illustrates all of the initial Sherpa settings; since no models have been defined, none are shown.
Report on the model components of different source models:
sherpa> READ DATA 1 example1.dat
sherpa> PARAMPROMPT OFF
Model parameter prompting is off
sherpa> POLY[modela]
sherpa> GAUSS[modelb]
sherpa> SOURCE 1 = modela
sherpa> SOURCE 2 = modelb
sherpa> SHOW SOURCE 1
Source 1: modela
polynom1d[modela] (integrate: on)
Param Type Value Min Max Units
----- ---- ----- --- --- -----
1 c0 thawed 33 -1 65
2 c1 frozen 0 -914.2857 914.2857
3 c2 frozen 0 -130.6122 130.6122
4 c3 frozen 0 -1 65
5 c4 frozen 0 -1 65
6 c5 frozen 0 -1 65
7 c6 frozen 0 -1 65
8 c7 frozen 0 -1 65
9 c8 frozen 0 -1 65
10 offset frozen 0 -1 8
sherpa> SHOW SOURCE 2
Source 2: modelb
gauss1d[modelb] (integrate: on)
Param Type Value Min Max Units
----- ---- ----- --- --- -----
1 fwhm thawed 5.1306 5.1306e-02 513.0582
2 pos thawed 8 1 8
3 ampl thawed 65 0.65 6500
Defines the source model expression to be used for fitting a dataset. The command SRC is an abbreviated equivalent.
sherpa> SOURCE [<dataset range> | ALLSETS] = <modelExpr>
![]() dataset range
dataset range![]()
![]() # (or more generally #:#,#:#, etc.) such that
# specifies a dataset number and #:# represents an inclusive range of datasets;
one may specify multiple inclusive ranges by separating them with
commas. The default dataset is dataset 1.
# (or more generally #:#,#:#, etc.) such that
# specifies a dataset number and #:# represents an inclusive range of datasets;
one may specify multiple inclusive ranges by separating them with
commas. The default dataset is dataset 1.
The model expression,
![]() modelExpr
modelExpr![]() ,
is an algebraic combination of one or more of the following elements:
,
is an algebraic combination of one or more of the following elements:
{<sherpa_modelname> | <sherpa_modelname>[modelname] |
<modelname> | <model_stack> | <nested_model>}
along with numerical values. The following operators are
recognized: ![]() - * / ( ) { }.
See the CREATE command for further information.
- * / ( ) { }.
See the CREATE command for further information.
Note that:
To reset a source model stack, issue the command:
sherpa> SOURCE [<dataset range> | ALLSETS] =
Examples:
Establish a model component, and define it as the source model to be used for fitting a specific dataset:
sherpa> SOURCE 2 = GAUSS GAUSS.fwhm parameter value [10] GAUSS.pos parameter value [0] GAUSS.ampl parameter value [1] sherpa>
This command defines the Sherpa model GAUSS
as the source model to be used for fitting dataset number 2.
Note that the user accepted the given initial values for
all of the parameters, using the ![]() RETURN
RETURN![]() key.
key.
Establish a model component and assign it a name; define the model component as the source model to be used for fitting a specific dataset:
sherpa> PARAMPROMPT OFF Model parameter prompting is off sherpa> GAUSS[modelb] sherpa> SOURCE 2 = modelb
In the first command, the name modelb is given to the Sherpa model component GAUSS (see the CREATE command for more information on the model language syntax). The second command defines this model as the source model to be used for fitting dataset number 2.
Establish model components, and assign them names; create a source model expression to be used for fitting a specific dataset:
sherpa> POW[modelc] sherpa> GAUSS[modelf] sherpa> SOURCE 1 = modelc + modelf
The last command in this series assigns
the model expression modelc ![]() modelf
as the source model to be used for fitting dataset number 1.
The following commands each assign
various other model expressions
to source models for dataset numbers 2, 3, and 4 respectively:
modelf
as the source model to be used for fitting dataset number 1.
The following commands each assign
various other model expressions
to source models for dataset numbers 2, 3, and 4 respectively:
sherpa> SOURCE 2 = 10*(modelc + modelf) sherpa> SOURCE 3 = (modelc - modelf)/2 sherpa> SOURCE 4 = 0.5*modelc + 0.7*modelf
See the CREATE command for further information about creating model expressions.
Establish a model component, assign it a name, and define it as the source model to be used for fitting:
sherpa> ERASE ALL sherpa> SOURCE 1 = POW[modelc]
In this single command, the name modelc is assigned to the Sherpa model component POW, and then this model is defined as the source model to be used for fitting dataset number 1.
Establish model components, assign them names, and use them to define a source model expression to be used for fitting:
sherpa> ERASE ALL sherpa> SOURCE 2 = GAUSS[modelb] + POW[modelc]
In this single command, the following is performed: the name modelb is assigned to the Sherpa model component GAUSS; the name modelc is assigned to the Sherpa model component POW; a model expression, which here is the sum of these two models components, is defined as the source model to be used for fitting dataset number 2.
Establish a model component, assign it a name, define the parameters, and define it as the source model to be used for fitting:
sherpa> ERASE ALL sherpa> SOURCE = POLY[modela](3.0:1.0:4.0)
With this single command, the name modela is assigned to the Sherpa model component POLY, the value of 3.0 is given to the model's first parameter (in this case parameter c0), the minimum of 1.0 is set for this parameter, the maximum of 4.0 is set for this parameter, and then this model is defined as the source model to be used for fitting dataset number 1.
Establish multiple model components, assign them names, and use them in a source model expression definition:
sherpa> SOURCE 2 = GAUSS[modelb](3:2.5:4.403, 1:-10:10, 1:-3.5:3.5)
+ POW[modelc]
With this single command, the following is performed: the name modelb is assigned to the Sherpa model component GAUSS; various parameter values and ranges are set for the parameters of modelb; the name modelc is assigned to the Sherpa model component POW; a model expression, which is the sum of these two models, is defined as the source model to be used for fitting dataset number 2.
Establish continuum and line model stacks, and combine these stacks into a source model expression definition:
sherpa> PARAMPROMPT OFF sherpa> CONT = POWLAW1D[modeld] sherpa> ELINE = NGAUSS[modele] sherpa> SOURCE = CONT + ELINE
In the second and third commands, the names modeld and modele are assigned to the Sherpa model components POWLAW1D and NGAUSS respectively; these model components are then assigned to the user-defined model stacks CONT and ELINE. These model stacks are then assigned to the source model expression.
Causes the specified 2-D data to be displayed, with a surface plot, via ChIPS.
sherpa> SPLOT [<num_plots>] <arg_1> [# [ID]] [<arg_2> [# [ID]] ...]
![]() num_plots
num_plots![]() specifies the number of plotting windows to
open within the ChIPS pane (default 1); that number sets the
number of subsequent arguments. For each subsequent argument,
# specifies the number of the dataset
(default dataset number is 1),
and the ID modifier is used for displaying background datasets,
and then if and only if
the Sherpa state
object variable multiback is set to 1,
i.e., if more than
one background dataset is to be associated with a single source dataset.
The ID modifier may be any unreserved string
(e.g., A, foo, etc.), i.e.,
a string that is not a parsable command.
specifies the number of plotting windows to
open within the ChIPS pane (default 1); that number sets the
number of subsequent arguments. For each subsequent argument,
# specifies the number of the dataset
(default dataset number is 1),
and the ID modifier is used for displaying background datasets,
and then if and only if
the Sherpa state
object variable multiback is set to 1,
i.e., if more than
one background dataset is to be associated with a single source dataset.
The ID modifier may be any unreserved string
(e.g., A, foo, etc.), i.e.,
a string that is not a parsable command.
The argument ![]() arg_n
arg_n![]() may be any of the following:
may be any of the following:
| Argument | Displays |
|---|---|
| {{DATA |
The source |
| {ERRORS |
The estimated total errors for the source |
| {SYSERRORS |
The assigned systematic errors for the source |
| {STATERRORS |
The estimated statistical errors for the source |
| {{MODEL |
The (convolved) source |
| {DELCHI |
The sigma residuals of the source |
| {RESIDUALS |
The absolute residuals of the source |
| {RATIO |
The ratio (data/model) for source |
| {CHI SQU |
The contributions to the |
| {STATISTIC |
The contributions to the current statistic
from each source |
| {WEIGHT |
The statistic weight value assigned to each source |
| {FILTER |
The mask value (0 |
| The (unconvolved) model amplitudes for the
specified model stack (SOURCE,
{BACKGROUND |
|
| The (unconvolved) model amplitudes for the specified user-defined model stack | |
| The (unconvolved) amplitudes of the specified model component (e.g., GAUSS2D) | |
| The (unconvolved) amplitudes of the specified model component (e.g., g) | |
| {EXPMAP |
The unfiltered source |
| {PSF |
The unfiltered source |
If there is no open plotting window when an SPLOT command is given, one will be created automatically.
If one issues the SPLOT following filtering,
note the following: arbitrarily
filtered data cannot be passed from Sherpa
to ChIPS for display; the data grid must be rectangular.
Therefore, surface plots are created in three steps: (1)
the smallest possible rectangle is drawn around the noticed data;
(2) within this rectangle, the
![]() data to image
data to image![]() is tranformed to
is tranformed to
![]() data to image
data to image![]() * filter; and (3)
these transformed data are sent off to ChIPS for display.
* filter; and (3)
these transformed data are sent off to ChIPS for display.
The appearance of plots generated with this command can be changed by modifying the fields of certain state objects. See the ahelp for Sherpa or for sherpa.plot for more information.
NOTE: all ChIPS commands may be used from within Sherpa to modify plot characteristics. In order to view these changes, the REDRAW command must be issued.
See the display chapter for more information regarding data display capabilities, including modifying various plot characteristics.
Examples:
Display 2-D data with a surface plot:
sherpa> DATA 3 example2Da.dat ASCII 1 2 3 sherpa> SPLOT DATA 3
The SPLOT command plots dataset number 3 as a surface plot. Dataset number 3 must be a 2-D dataset.
Display 2-D datasets with surface plots in multiple windows:
sherpa> DATA 1 example2Db.dat ASCII 1 2 3 sherpa> SPLOT 2 DATA 1 DATA 3
This command displays a surface plot of dataset number 1 (example2Db.dat) in the first window, and a surface plot of dataset number 3 (example2Da.dat) in the second window.
Specifies the fitting statistic.
sherpa> STATISTIC <sherpa_statisticname>
![]() sherpa_statisticname
sherpa_statisticname![]() is the name of one of the
supported fitting statistics:
is the name of one of the
supported fitting statistics:
| Description | |
|---|---|
| BAYES | A Bayesian maximum likelihood function. |
| CASH | A maximum likelihood function. |
| {CHI CVAR |
|
| CHI DVAR | |
| CHI GEHRELS | |
| CHI MVAR | |
| CHI PRIMINI | |
| CSTAT | A maximum likelihood function: XSPEC implementation of CASH |
| USERSTAT | User-implemented statistic. |
The default statistic is CHI GEHRELS. It is the default because of its behavior in the low-counts regime.
The statistic that has been set in the current Sherpa session may be listed with the command SHOW STATISTIC.
Examples:
Specify a fitting statistic to be used; report on it:
sherpa> STATISTIC BAYES sherpa> SHOW STATISTIC Statistic: Bayes
Performs background subtraction.
sherpa> SUBTRACT [<dataset range> | ALLSETS]
where ![]() dataset range
dataset range![]()
![]() #, or more generally #:#,#:#,...,
such that
# specifies a dataset number, and #:# represents an inclusive range of datasets;
one may specify multiple inclusive ranges by separating them
with commas. The default dataset is dataset 1.
#, or more generally #:#,#:#,...,
such that
# specifies a dataset number, and #:# represents an inclusive range of datasets;
one may specify multiple inclusive ranges by separating them
with commas. The default dataset is dataset 1.
The SUBTRACT performs background subtraction on a channel-by-channel basis:
![$\displaystyle S_i'~=~S_i - \beta_S t_S \left[ \frac{B_i}{\beta_B t_B} \right] \,,$](img69.gif) |
(1.6) |
The SUBTRACT command may only be used when:
Unless the user specifies errors for the background-subtracted data, the errors are computed automatically by propagating the errors for source and background data.
To undo background subtraction, use the command UNSUBTRACT.
Alternative means of subtracting and unsubtracting involve using the Sherpa/S-Lang module functions set_subtract and set_unsubtract.
Note that while XSPEC automatically performs background subtraction, in Sherpa one must directly issue the command SUBTRACT.
Examples:
Read in source and background data, then subtract.
sherpa> DATA example2.pha
...
Background data are being input from:
<directory_path>/example2_bkg.pha
sherpa> PLOTY COUNTS
sherpa> WRITE DATA
Write X-Axis: Energy (keV) Y-Axis: Flux (Counts)
...
0.4286 13
0.4573 15
0.5002 25
0.5575 21
...
sherpa> SUBTRACT
Write X-Axis: Energy (keV) Y-Axis: Flux (Counts)
...
0.4286 5.2974
0.4573 6.9893
0.5002 10.8273
0.5575 6.2111
...
sherpa> UNSUBTRACT
Write X-Axis: Energy (keV) Y-Axis: Flux (Counts)
...
0.4286 13
0.4573 15
0.5002 25
0.5575 21
...
Defines an expression or file to be used to specify the statistical errors for source data.
sherpa> [B]STATERRORS [<dataset range> | ALLSETS] = <errorExpr>
STATERRORS is used for specifying statistical errors in source datasets, while BSTATERRORS is used for specifying statistical errors in background datasets.
![]() dataset range
dataset range![]()
![]() #
(or more generally #:#,#:#, etc.) such that
#
specifies a dataset number and #:#
represents an inclusive range of datasets;
one may specify multiple inclusive ranges by separating them with
commas. The default dataset is dataset 1.
#
(or more generally #:#,#:#, etc.) such that
#
specifies a dataset number and #:#
represents an inclusive range of datasets;
one may specify multiple inclusive ranges by separating them with
commas. The default dataset is dataset 1.
The error expression, ![]() errorExpr
errorExpr![]() , may be composed of one or
more (algebraically-combined) of the following elements:
, may be composed of one or
more (algebraically-combined) of the following elements:
| Component: | Description: |
| DATA | An input dataset |
| numericals | Numerical values |
| operators |
A few things to note:
For additional information, see the related command ERRORS.
Examples:
Define an expression to be used for the statistical errors.
sherpa> DATA data.dat sherpa> STATERRORS = 5
Defines an expression or file to be used to specify the systematic errors for source data.
sherpa> SYSERRORS [<dataset range> | ALLSETS] = <errorExpr>
SYSERRORS is used for specifying statistical errors in source datasets, while BSYSERRORS is used for specifying statistical errors in background datasets ("ahelp bsyserrors").
![]() dataset range
dataset range![]()
![]() #
(or more generally #:#,#:#, etc.) such that
#
specifies a dataset number and #:#
represents an inclusive range of datasets;
one may specify multiple inclusive ranges by separating them with
commas. The default dataset is dataset 1.
#
(or more generally #:#,#:#, etc.) such that
#
specifies a dataset number and #:#
represents an inclusive range of datasets;
one may specify multiple inclusive ranges by separating them with
commas. The default dataset is dataset 1.
The error expression, ![]() errorExpr
errorExpr![]() , may be composed of one or
more (algebraically-combined) of the following elements:
, may be composed of one or
more (algebraically-combined) of the following elements:
| Component: | Description: |
| DATA | An input dataset |
| numericals | Numerical values |
| operators |
A few things to note:
For additional information, see the related command ERRORS.
The systematic errors are accessible to the Sherpa/S-Lang module user via the functions get_syserrors and set_syserrors.
Examples:
Define an expression to be used for the systematic errors. In each bin, they will be computed as 0.1 times the datum.
sherpa> DATA data.dat sherpa> SYSERRORS = 0.1
Allows model parameter(s) to vary.
sherpa> THAW <arg_1> [<arg_2> ...]
![]() arg
arg![]() may be:
may be:
| Argument | Description |
|---|---|
| Thaws the specified model component parameter. | |
| Thaws the specified model component parameter. | |
| Thaws all parameters of the specified model component. | |
| Thaws all parameters of the specified model component. | |
| Thaws the parameters of all model components within the
specified model stack (SOURCE, BACKGROUND,
PILEUP, |
|
| Thaws the parameters of all model components within the user-defined model stack. |
The command FREEZE is used to prohibit model parameter values from varying.
In addition, model parameters may be thawed using the equivalent command
Model parameters may also be thawed using the Sherpa/S-Lang module functions set_thawed and set_par.
Examples:
Thaw a model parameter:
sherpa> GAUSS[modelb] modelb.fwhm parameter value [10] modelb.pos parameter value [0] modelb.ampl parameter value [1] sherpa> THAW modelb.ampl
The final command thaws the parameter ampl of modelb.
Freeze a model parameter and thaw a model parameter:
sherpa> FREEZE modelb.3 sherpa> THAW modelb.3
First, the third parameter of modelb is frozen. The last command then thaws the third parameter of modelb.
Freeze all model parameters and thaw two model parameters:
sherpa> FREEZE modelb sherpa> THAW modelb.fwhm modelb.pos
First, all parameters of modelb are frozen. The last command then thaws the fwhm and pos parameters of modelb.
Freeze or thaw all source component parameters at once:
sherpa> PARAMPROMPT OFF
Model parameter prompting is off
sherpa> POW[modelc]
sherpa> GAUSS[modelf]
sherpa> SOURCE 2 = modelc + modelf
sherpa> FREEZE SOURCE 2
sherpa> SHOW SOURCE 2
Source 2:
(modelc + modelf)
powlaw1d[modelc] (integrate: on)
Param Type Value Min Max Units
----- ---- ----- --- --- -----
1 gamma frozen 1 -10 10
2 ref frozen 1-3.4028e+38 3.4028e+38
3 ampl frozen 1 1e-20 3.4028e+38
gauss1d[modelf] (integrate: on)
Param Type Value Min Max Units
----- ---- ----- --- --- -----
1 fwhm frozen 10 1.1755e-38 3.4028e+38
2 pos frozen 0-3.4028e+38 3.4028e+38
3 ampl frozen 1-3.4028e+38 3.4028e+38
sherpa> THAW SOURCE 2
sherpa> SHOW SOURCE 2
(modelc + modelf)
powlaw1d[modelc] (integrate: on)
Param Type Value Min Max Units
----- ---- ----- --- --- -----
1 gamma thawed 1 -10 10
2 ref frozen 1-3.4028e+38 3.4028e+38
3 ampl thawed 1 1e-20 3.4028e+38
gauss1d[modelf] (integrate: on)
Param Type Value Min Max Units
----- ---- ----- --- --- -----
1 fwhm thawed 10 1.1755e-38 3.4028e+38
2 pos thawed 0-3.4028e+38 3.4028e+38
3 ampl thawed 1-3.4028e+38 3.4028e+38
This example illustrates the use of FREEZE SOURCE and THAW SOURCE to freeze and thaw all source component parameters at once, respectively. Note that thawing of some model parameters (e.g., POWLAW1D.ref) is not permitted.
Thaw a model parameter:
sherpa> modelb.ampl.TYPE = THAW
This command thaws the parameter ampl of modelb. The following commands are each equivalent:
sherpa> modelb.3.TYPE = THAW sherpa> THAW modelb.ampl sherpa> THAW modelb.3
Freeze all model parameters at once and thaw all source parameters at once:
sherpa> PARAMPROMPT OFF
Model parameter prompting is off
sherpa> DATA data/example.pha
sherpa> GAUSS[modelc]
sherpa> SOURCE = modelb + modelc
sherpa> FREEZE modelc
sherpa> SHOW SOURCE
(modelb + modelc)
gauss1d[modelb] (integrate: on)
Param Type Value Min Max Units
----- ---- ----- --- --- -----
1 fwhm frozen 2 1.1755e-38 3.4028e+38
2 pos frozen 0-3.4028e+38 3.4028e+38
3 ampl thawed 1-3.4028e+38 3.4028e+38
gauss1d[modelc] (integrate: on)
Param Type Value Min Max Units
----- ---- ----- --- --- -----
1 fwhm frozen 0.7113 0.0071 71.1283
2 pos frozen 0.9442 0.0276 14.5494
3 ampl frozen 0.0001 1.0564e-06 0.0106
sherpa> THAW SOURCE
sherpa> SHOW SOURCE
(modelb + modelc)
gauss1d[modelb] (integrate: on)
Param Type Value Min Max Units
----- ---- ----- --- --- -----
1 fwhm thawed 2 1.1755e-38 3.4028e+38
2 pos thawed 0-3.4028e+38 3.4028e+38
3 ampl thawed 1-3.4028e+38 3.4028e+38
gauss1d[modelc] (integrate: on)
Param Type Value Min Max Units
----- ---- ----- --- --- -----
1 fwhm thawed 0.7113 0.0071 71.1283
2 pos thawed 0.9442 0.0276 14.5494
3 ampl thawed 0.0001 1.0564e-06 0.0106
Note that the command FREEZE modelc freezes all parameters of the source model component modelc, while THAW SOURCE thaws all parameters of both source model components.
Resets negative model amplitudes to zero.
sherpa> TRUNCATE [<dataset range> | ALLSETS] [{ON | OFF}]
where ![]() dataset range
dataset range![]()
![]() #, or more generally #:#,#:#,...,
such that
# specifies a dataset number, and #:# represents an inclusive range of datasets;
one may specify multiple inclusive ranges by separating them
with commas. The default dataset is dataset number 1.
#, or more generally #:#,#:#,...,
such that
# specifies a dataset number, and #:# represents an inclusive range of datasets;
one may specify multiple inclusive ranges by separating them
with commas. The default dataset is dataset number 1.
The command TRUNCATE resets any negative model amplitudes
to zero (actually, ![]() ); truncation is
necessary for the Poisson-likelihood-based statistics of
Sherpa
(BAYES,
CASH,
and
CSTAT) to work properly (none of these
statistics allows negative model amplitudes). Note that:
); truncation is
necessary for the Poisson-likelihood-based statistics of
Sherpa
(BAYES,
CASH,
and
CSTAT) to work properly (none of these
statistics allows negative model amplitudes). Note that:
Examples:
Fitting with a linear model, using the Cash statistic:
sherpa> READ DATA example1.dat
sherpa> PARAMPROMPT OFF
Model parameter prompting is off
sherpa> SOURCE = POLYNOM1D[my]
sherpa> THAW my.c1
sherpa> my.c0.min = -10
sherpa> METHOD SIMPLEX
sherpa> STATISTIC CASH
sherpa> TRUNCATE OFF
sherpa> FIT
smplx: v1.3
smplx: initial statistic value = -9.05568E+02
Error: predicted data are zero or negative.
-- Apply commands RESET and TRUNCATE ON, and refit.
sherpa> RESET
sherpa> TRUNCATE
Model Truncation for Dataset 1: off
sherpa> TRUNCATE ON
sherpa> FIT
smplx: v1.3
smplx: initial statistic value = -9.05568E+02
smplx: converged to minimum = -1.05814E+03 at iteration = 67
smplx: final statistic value = -1.05814E+03
my.c0 -6.61366
my.c1 7.16072
Estimates confidence intervals for selected thawed parameters.
sherpa> UNCERTAINTY [<dataset range> | ALLSETS] [ <arg_1> , ... ]
where ![]() dataset range
dataset range![]()
![]() #, or more generally #:#,#:#,...,
such that # specifies a dataset number, and #:# represents an
inclusive range of datasets; one may specify multiple inclusive ranges
by separating them with commas. The default
is to estimate limits using data from all appropriate datasets.
#, or more generally #:#,#:#,...,
such that # specifies a dataset number, and #:# represents an
inclusive range of datasets; one may specify multiple inclusive ranges
by separating them with commas. The default
is to estimate limits using data from all appropriate datasets.
The command-line arguments ![]() arg_n
arg_n![]() may be:
may be:
| Argument | Description |
|---|---|
| A specified model component parameter (e.g., GAUSS.pos). | |
| A specified model component parameter (e.g., g.pos). |
The user may configure UNCERTAINTY via the Sherpa state object structure unc. The current values of the fields of this structure may be displayed using the command print(sherpa.unc), or using the more verbose Sherpa/S-Lang module function list_unc().
The structure fields are:
| Field | Description |
|---|---|
| sigma | Specifies the number of |
| eps | The tolerance for sigma, influencing the numerical accuracy of the errorbars. (Decreasing eps increases errorbar accuracy.) |
| remin | If in the course of computing the interval, a statistic value is found that is less than the previous best-fit by more than remin, a new fit will be started; after minimization, UNCERTAINTY will run to completion. |
Field values may be set using directly, e.g.,
sherpa> sherpa.unc.sigma = 2.6
NOTE: strict checking of value inputs is not done, i.e., the user can errantly change arrays to scalars, etc. To restore the default settings of the structure at any time, use the Sherpa/S-Lang module function restore_unc().
Confidence interval bounds are determined for each parameter in turn. A given parameter's value is varied while the values of all the other nominally thawed parameters are held fixed to their best-fit values. This is a simplistic method of estimating confidence interval bounds that gives truly accurate results only in special cases, as explained below.
Because UNCERTAINTY estimates confidence
intervals for each parameter independently, the relationship between
UNCERTAINTY.sigma and the change in statistic value ![]() can be particularly simple:
can be particularly simple:
![]() for statistics sampled
from the
for statistics sampled
from the ![]() distribution and for
the Cash statistic, and is approximately equal to
distribution and for
the Cash statistic, and is approximately equal to
![]() for fits based on the general log-likelihood (
for fits based on the general log-likelihood (
![]() ).
).
| Confidence |
|
|
|
| 68.3% | 1.0 | 1.00 | 0.50 |
| 90.0% | 1.6 | 2.71 | 1.36 |
| 95.5% | 2.0 | 4.00 | 2.00 |
| 99.0% | 2.6 | 6.63 | 3.32 |
| 99.7% | 3.0 | 9.00 | 4.50 |
One may determine if these conditions hold, for example, by plotting
the fit statistic as a function of each parameter's values (the curve
should approximate a parabola) and by examining contour plots of the
fit statistics made by varying the values of two parameters at a time
(the contours should be elliptical, with principal axes aligned along
the parameter axes, and parameter space boundaries should be no closer
than approximately ![]() from the best-fit point).
from the best-fit point).
If the second and third conditions hold, but the first does not, then the confidence intervals may be determined by using either COVARIANCE and PROJECTION.
If none of the conditions hold, then the output from UNCERTAINTY is meaningless except that it would give an idea of the scale of the confidence intervals. To accurately determine the confidence intervals, one would have to reparameterize the model, or use Monte Carlo simulations or Bayesian methods.
Examples:
List the current and default values of the unc structure, and restore the default values:
sherpa> sherpa.unc.sigma = 5 sherpa> list_unc() Parameter Current Default Description ---------------------------------------------------------------------- sigma 5 1 Number of sigma eps 0.01 0.01 Tolerance for sigma remin 0.01 0.01 Thresh stat change to reminimize sherpa> restore_unc() sherpa> list_unc() Parameter Current Default Description ---------------------------------------------------------------------- sigma 1 1 Number of sigma eps 0.01 0.01 Tolerance for sigma remin 0.01 0.01 Thresh stat change to reminimize
Search parameter space to find a range of parameter values within a confidence interval of 90.0% for all thawed parameters:
sherpa> READ DATA example1.dat
sherpa> PARAMPROMPT OFF
Model parameter prompting is off
sherpa> SOURCE = POLYNOM1D[my]
sherpa> THAW my.c1 my.c2
sherpa> METHOD SIMPLEX
sherpa> FIT
...
sherpa> sherpa.unc.sigma = 1.6
sherpa> UNCERTAINTY
WARNING: found better fit -- reminimizing!
smplx: v1.3
smplx: initial statistic value = 3.33768E-01
smplx: converged to minimum = 3.30123E-01 at iteration = 12
smplx: final statistic value = 3.30123E-01
my.c0 -0.861519
my.c1 0.672815
my.c2 0.919114
Computed for uncertainty.sigma = 1.6
--------------------------------------------------------
Parameter Name Best-Fit Lower Bound Upper Bound
--------------------------------------------------------
my.c0 -0.861519 -2.32896 +2.45363
my.c1 0.672815 -0.757506 +0.730418
my.c2 0.919114 -0.133193 +0.131418
Search parameter space to find a range of parameter values within a confidence interval of 68.3% for the parameters my.c0 and my.c1:
sherpa> sherpa.unc.sigma = 1.0
sherpa> UNCERTAINTY my.c0 my.c1
Computed for uncertainty.sigma = 1
--------------------------------------------------------
Parameter Name Best-Fit Lower Bound Upper Bound
--------------------------------------------------------
my.c0 -0.861519 -1.4335 +1.56432
my.c1 0.672815 -0.479026 +0.450944
Causes Sherpa to undo a grouping scheme that had been applied to source or background data.
sherpa> [B]UNGROUP [# [ID]]
UNGROUP is used to ungroup source data, while BUNGROUP is used to ungroup background data.
# specifies the number of the dataset to which the grouping scheme is to be applied (default dataset number is 1). The ID modifier is used if and only if the Sherpa state object variable multiback is set to 1, i.e., if more than one background dataset is to be associated with a single source dataset. The ID modifier may be any unreserved string (e.g., A, foo, etc.), i.e., a string that is not a parsable command.
The commands GROUP and UNGROUP allow a user to toggle back and forth between the analysis of grouped and ungrouped data, after grouping assignments have been read into Sherpa via the command READ GROUPS. (In a future version of Sherpa, the GROUP may be issued automatically upon the reading in of groups.)
Note the issuing the UNGROUP causes Sherpa to delete any defined filters for the specified dataset.
NOTE: in CIAO 3.0, the commands GROUP and UNGROUP may not be used with PHA data that has a GROUPING column. This is because these data are grouped before Sherpa ever has control of them, and Sherpa thus has no knowledge of how the ungrouped data are distributed among bins. This will be changed in a future version of Sherpa.
See the documentation on the GROUP command for more details and an example.
Removes a link between model parameters.
sherpa> UNLINK <arg>
The command-line argument ![]() arg
arg![]() may be:
may be:
| Argument | Description |
|---|---|
| A specified model component parameter (e.g., GAUSS.pos). | |
| A specified model component parameter (e.g., g.pos). |
A link between two model parameters is established using the
![]()
![]() operator (see examples, below); UNLINK
breaks the link.
When a link is removed between model parameters, the parameter value
will be that of the parameter to which it had been linked.
When a link
is removed between a model parameter and a model stack, the parameter
value will return to its value before such a link was established.
operator (see examples, below); UNLINK
breaks the link.
When a link is removed between model parameters, the parameter value
will be that of the parameter to which it had been linked.
When a link
is removed between a model parameter and a model stack, the parameter
value will return to its value before such a link was established.
Examples:
Set up, and then remove, a link between model parameters:
sherpa> ERASE ALL sherpa> PARAMPROMPT ON Model parameter prompting is on sherpa> GAUSS[modelb] modelb.fwhm parameter value [10] modelb.pos parameter value [0] modelb.ampl parameter value [1] sherpa> GAUSS[modelf] modelf.fwhm parameter value [10] modelf.pos parameter value [0] modelf.ampl parameter value [1] sherpa> modelf.ampl => 0.5*modelb.ampl
The last command in this series uses a model parameter expression, to link the ampl parameter of modelf to 0.5 multiplied by the ampl parameter of modelb. That is, the amplitudes of two Gaussian models are linked, where one is half that of the other. Note that model parameter expressions cannot be created within the model parameter prompting. The link may be broken as follows:
sherpa> UNLINK modelf.ampl
Set up, and then remove, links between model parameters:
sherpa> PARAMPROMPT OFF Model parameter prompting is off sherpa> POW[modelc] sherpa> POW[modeld] sherpa> POW[modele] sherpa> modelc.1 => modele.1 sherpa> modelc.3 => 2*modeld.3 - modele.3
The next-to last command in this series links the first parameter (gamma) of modelc to the first parameter of modele. The last command in this series links the third parameter (ampl) of modelc to the parameter expression: 2 multiplied by the third parameter of modeld, minus the third parameter of modele. The links may be broken as follows:
sherpa> UNLINK modelc.1 sherpa> UNLINK modelc.3
Undoes background subtraction.
sherpa> UNSUBTRACT [<dataset range> | ALLSETS]
where ![]() dataset range
dataset range![]()
![]() #, or more generally #:#,#:#,...,
such that
# specifies a dataset number, and #:# represents an inclusive range of datasets;
one may specify multiple inclusive ranges by separating them
with commas. The default dataset is dataset 1.
#, or more generally #:#,#:#,...,
such that
# specifies a dataset number, and #:# represents an inclusive range of datasets;
one may specify multiple inclusive ranges by separating them
with commas. The default dataset is dataset 1.
The UNSUBTRACT restores the input source dataset amplitudes to the Sherpa session.
See the documentation on the SUBTRACT command for more details and an example.
Calls and executes a Sherpa script.
sherpa> USE <script_name>
where ![]() script_name
script_name![]() is the name
of an ASCII file containing Sherpa commands.
A Sherpa script should contain Sherpa commands
as they would be typed on the Sherpa
command-line. Comments may be placed
in the script by putting a
# symbol at the start of the line.
is the name
of an ASCII file containing Sherpa commands.
A Sherpa script should contain Sherpa commands
as they would be typed on the Sherpa
command-line. Comments may be placed
in the script by putting a
# symbol at the start of the line.
Note that Sherpa scripts may also be run directly from the UNIX command line, using the following syntax:
unix% sherpa ![]() script_name
script_name![]()
Note that when a script is run, either from within Sherpa or from the UNIX command line, parameter prompting is automatically turned off. Thus there is no need to include a PARAMPROMPT OFF command in the script.
Also note that if a {BYE ![]() EXIT
EXIT ![]() QUIT} command is not given
in the script, control over the Sherpa session will revert to the user
when Sherpa finishes processing the scripted commands.
QUIT} command is not given
in the script, control over the Sherpa session will revert to the user
when Sherpa finishes processing the scripted commands.
Sherpa scripts may be created by using the SAVE command.
Examples:
Call and execute a Sherpa script:
sherpa> $more example.script # This is my sherpa script READ DATA data/example1.dat PARAMPROMPT OFF POLY[modela] THAW modela.2 modela.3 SOURCE = modela FIT sherpa> USE example.script
Reports the Sherpa version that is in use.
sherpa> VERSION Sherpa Version 3.0.2 sherpa> print( sherpa_version ); 30002
The version of Sherpa is displayed when it is started up in interactive mode. It can also be found by using the VERSION command, which displays a message on the screen.
The value can also be accessed from a S-Lang script by using the sherpa_version variable. This returns the version using the following formula
| (1.7) |
| (1.8) |
Causes the specified information to be written to the screen or to a file.
sherpa> WRITE <arg> [# [ID]] [<filename> [<filetype>]]
# specifies the number of the dataset (default dataset number is 1). The ID modifier is used for writing background datasets, and then if and only if the Sherpa state object variable multiback is set to 1, i.e., if more than one background dataset is to be associated with a single source dataset. The ID modifier may be any unreserved string (e.g., A, foo, etc.), i.e., a string that is not a parsable command.
The name of the file to which data is written is
![]() filename
filename![]() . If
. If ![]() filename
filename![]() is not specified, information is written to the screen.
is not specified, information is written to the screen.
The argument ![]() arg_n
arg_n![]() may be any of the following:
may be any of the following:
| Argument | Displays |
|---|---|
| {DATA |
The source data values |
| {BACK |
The background data values |
| ERRORS | The errors associated with source data points |
| BERRORS | The errors associated with background data points |
| {SYSERRORS |
The assigned systematic errors for the source |
| {STATERRORS |
The estimated statistical errors for the source |
| {{MODEL |
The (convolved) source |
| {DELCHI |
The sigma residuals of the source |
| {RESIDUALS |
The absolute residuals of the source |
| {RATIO |
The ratio (data/model) for source |
| {CHI SQU |
The contributions to the |
| {STATISTIC |
The contributions to the current statistic |
| {WEIGHT |
The statistic weight value assigned to each source |
| {FILTER |
The mask value (0 |
| {GROUP |
The grouping value (1 |
| {QUALITY |
The quality value (0 |
| The (unconvolved) model amplitudes for the
specified model stack (SOURCE,
{BACKGROUND |
|
| The (unconvolved) model amplitudes for the specified user-defined model stack | |
| The (unconvolved) amplitudes of the specified model component (e.g., GAUSS) | |
| The (unconvolved) amplitudes of the specified model component (e.g., g) | |
| {ARF |
The unfiltered source |
| {EXPMAP |
The unfiltered source |
| {PSF |
The unfiltered source |
| MDL | A model descriptor list file. |
The argument ![]() filetype
filetype![]() can specify the
desired format for the file that is written:
can specify the
desired format for the file that is written:
| Description | |
|---|---|
| ASCII | 1-D ASCII |
| FITS | 2-D FITS image |
| FITSIMAGE | 2-D FITS image |
| FITSBIN | 1-D FITS binary table |
| PHA | PHA file |
Note the following:
The WRITE command may be issued at any time. Each time
the command is issued the specified file
![]() filename
filename![]() is overwritten, but only if the
state variable sherpa.clobber is set to 1. Otherwise, an
error message is displayed if the file exists.
is overwritten, but only if the
state variable sherpa.clobber is set to 1. Otherwise, an
error message is displayed if the file exists.
unix% dmcopy "infile.fits[spec 1][spec 2]" outfile.fits
you can also do
sherpa> write "infile.fits[spec 1][spec 2]"
This is especially useful when working with very large files. For example:
sherpa> write "evt.fits[bin sky=4][opt mem=100]"
bins the event file by a factor of four and allocates additional memory.
Examples:
Write an ASCII dataset to a backup ASCII file:
sherpa> READ DATA 2 example.dat 1 2 sherpa> WRITE DATA 2 example_backup.dat Write X-Axis: Bin Y-Axis: Flux (Counts) sherpa> WRITE DATA 2 example_backup.dat Write X-Axis: Bin Y-Axis: Flux (Counts) Error: file exists and sherpa.clobber = 0. sherpa> sherpa.clobber = 1 sherpa> WRITE DATA 2 example_backup.dat Write X-Axis: Bin Y-Axis: Flux (Counts)
The second command writes dataset number 2 to an ASCII file named example_backup.dat. This file cannot be overwritten unless the state variable sherpa.clobber is set to 1.
Write a PHA dataset to a backup ASCII file:
sherpa> READ DATA example.pha The inferred file type is PHA. If this is not what you want, please specify the type explicitly in the data command. WARNING: using systematic errors specified in the PHA file. RMF is being input from: <directory_path>/example.rmf ARF is being input from: <directory_path>/example.arf Background data are being input from: <directory_path>/example_bkg.pha sherpa> WRITE DATA pha.dat ASCII Write X-Axis: Energy (keV) Y-Axis: Flux (Counts/sec/keV)
Note that the ASCII argument in the command WRITE DATA pha.dat ASCII is not actually needed, since the default for 1-D data is ASCII format.
Extract three columns from a FITSBIN file and write them to an ASCII file:
sherpa> READ DATA "example1_bin.fits[cols x1,x2,x3]" FITSBIN sherpa> WRITE DATA threecols.txt ASCII 1 2 3 Write X-Axes: (Bin,Bin) Y-Axis: Counts
Make a fit to data and save the best-fit amplitudes for one of the model components, along with information about the fit:
sherpa> ERASE ALL
sherpa> READ DATA example1.dat
sherpa> PARAMPROMPT OFF
Model parameter prompting is off
sherpa> SOURCE = POLY[p1] + POW[p2]
sherpa> FIT
LVMQT: V2.0
LVMQT: initial statistic value = 3070.54
LVMQT: final statistic value = 0.252662 at iteration 14
p1.c0 0.256496
p2.gamma -2.03063
p2.ampl 15.6881
sherpa> WRITE p2 powlaw.mod ASCII
Write X-Axis: Bin Y-Axis: Flux (Photons/bin)
sherpa> WRITE SOURCE source.mod
Write X-Axis: Bin Y-Axis: Flux (Photons/bin)
sherpa> var1 = get_axes(1)
sherpa> print(var1)
axistype = Channels
axisunits = unknown
lo = NULL
hi = NULL
mid = Float_Type[8]
sherpa> var2 = get_data(1)
sherpa> var3 = get_errors(1)
sherpa> var4 = get_mcounts(1)
sherpa> writeascii("fit.dat",var1.mid,var2,var3,var4)
The last command writes out a 4-column file with x-axis values and associated data, errors, and predicted model counts.
Performs the XSPEC command abund.
sherpa> XSPEC ABUNDAN {<arg> | FILE <filename>}
where ![]() arg
arg![]() is one of the options listed in the
table below.
is one of the options listed in the
table below.
This commands sets the elemental abundance table used in XSPEC plasma-code models. (It does not set abundances for xswabs.)
| Name | Description |
|---|---|
| angr | default value; Anders E. & Grevesse N. (1989, Geochimica et Cosmochimica Acta 53, 197) |
| feld | Feldman U. (1992, Physica Scripta 46, 202) |
| aneb | Anders E. & Ebihara (1982, Geochimica et Cosmochimica Acta 46, 2363) |
| grsa | Grevesse, N. & Sauval, A.J. (1998, Space Science Reviews 85, 161) |
| wilm | Wilms, Allen & McCray (2000, ApJ 542, 914) |
| lodd | The solar photospheric abundances in Lodders, K (2003, ApJ 591, 1220) |
| file |
When using the command, the argument can be shortened as long as it remains unique; see Example 3 below.
All abundances are number relative to H.
| Element | angr | feld | aneb | grsa | wilm | lodd |
| H | 1.00e |
1.00e |
1.00e |
1.00e |
1.00e |
1.00e |
| He | 9.77e-2 | 9.77e-2 | 8.01e-2 | 8.51e-2 | 9.77e-2 | 7.92e-2 |
| Li | 1.45e-11 | 1.26e-11 | 2.19e-9 | 1.26e-11 | 0.00 | 1.90e-9 |
| B | 1.41e-11 | 2.51e-11 | 2.87e-11 | 2.51e-11 | 0.00 | 2.57e-11 |
| Be | 3.98e-10 | 3.55e-10 | 8.82e-10 | 3.55e-10 | 0.00 | 6.03e-10 |
| C | 3.63e-4 | 3.98e-4 | 4.45e-4 | 3.31e-4 | 2.40e-4 | 2.45e-4 |
| N | 1.12e-4 | 1.00e-4 | 9.12e-5 | 8.32e-5 | 7.59e-5 | 6.76e-5 |
| O | 8.51e-4 | 8.51e-4 | 7.39e-4 | 6.76e-4 | 4.90e-4 | 4.90e-4 |
| F | 3.63e-8 | 3.63e-8 | 3.10e-8 | 3.63e-8 | 0.00 | 2.88e-8 |
| Ne | 1.23e-4 | 1.29e-4 | 1.38e-4 | 1.20e-4 | 8.71e-5 | 7.41e-5 |
| Na | 2.14e-6 | 2.14e-6 | 2.10e-6 | 2.14e-6 | 1.45e-6 | 1.99e-6 |
| Mg | 3.80e-5 | 3.80e-5 | 3.95e-5 | 3.80e-5 | 2.51e-5 | 3.55e-5 |
| Al | 2.95e-6 | 2.95e-6 | 3.12e-6 | 2.95e-6 | 2.14e-6 | 2.88e-6 |
| Si | 3.55e-5 | 3.55e-5 | 3.68e-5 | 3.55e-5 | 1.86e-5 | 3.47e-5 |
| P | 2.82e-7 | 2.82e-7 | 3.82e-7 | 2.82e-7 | 2.63e-7 | 2.88e-7 |
| S | 1.62e-5 | 1.62e-5 | 1.89e-5 | 2.14e-5 | 1.23e-5 | 1.55e-5 |
| Cl | 1.88e-7 | 1.88e-7 | 1.93e-7 | 3.16e-7 | 1.32e-7 | 1.82e-7 |
| Ar | 3.63e-6 | 4.47e-6 | 3.82e-6 | 2.51e-6 | 2.57e-6 | 3.55e-6 |
| K | 1.32e-7 | 1.32e-7 | 1.39e-7 | 1.32e-7 | 0.00 | 1.29e-7 |
| Ca | 2.29e-6 | 2.29e-6 | 2.25e-6 | 2.29e-6 | 1.58e-6 | 2.19e-6 |
| Sc | 1.26e-9 | 1.48e-9 | 1.24e-9 | 1.48e-9 | 0.00 | 1.17e-9 |
| Ti | 9.77e-8 | 1.05e-7 | 8.82e-8 | 1.05e-7 | 6.46e-8 | 8.32e-8 |
| V | 1.00e-8 | 1.00e-8 | 1.08e-8 | 1.00e-8 | 0.00 | 1.00e-8 |
| Cr | 4.68e-7 | 4.84e-7 | 4.93e-7 | 4.68e-7 | 3.24e-7 | 4.47e-7 |
| Mn | 2.45e-7 | 2.45e-7 | 3.50e-7 | 2.45e-7 | 2.19e-7 | 3.16e-7 |
| Fe | 4.68e-5 | 3.24e-5 | 3.31e-5 | 3.16e-5 | 2.69e-5 | 2.95e-5 |
| Co | 8.60e-8 | 8.60e-8 | 8.27e-8 | 8.32e-8 | 8.32e-8 | 8.13e-8 |
| Ni | 1.78e-6 | 1.78e-6 | 1.81e-6 | 1.78e-6 | 1.12e-6 | 1.66e-6 |
| Cu | 1.62e-8 | 1.62e-8 | 1.89e-8 | 1.62e-8 | 0.00 | 1.82e-8 |
| Zn | 3.98e-8 | 3.98e-8 | 4.63e-8 | 3.98e-8 | 0.00 | 4.27e-8 |
This information is taken from the XSpec User's Guide. Version 11.3.1.x of the XSpec models is supplied with CIAO 3.4.
Examples:
Run the XSPEC command abund, setting abundances to Feldman:
sherpa> XSPEC ABUNDAN FELD
Abundances set to Feldman
Reset the abundances to the default value:
sherpa> XSPEC ABUNDAN ANGR
Abundances set to Anders & Grevesse
The argument can be shortened as long as it remains unique.
sherpa> XSPEC ABUNDAN W
Abundances set to Wilms et al.
sherpa> XSPEC ABUNDAN F
Abundances set to Feldman
sherpa> XSPEC ABUNDAN G
Abundances set to Grevesse & Sauval
In the case of the two arguments that begin with "AN", "ANGR" takes precedence over "ANEB" if only the first or second letter is given:
sherpa> XSPEC ABUNDAN A
Abundances set to Anders & Grevesse
sherpa> XSPEC ABUNDAN AN
Abundances set to Anders & Grevesse
sherpa> XSPEC ABUNDAN ANE
Abundances set to Anders & Ebihara
Read custom abundances from a file:
sherpa> XSPEC ABUNDAN FILE abund.txt
Abundances set to those read from file
Performs the XSPEC command xsect.
sherpa> XSPEC XSECT <arg>
where ![]() arg
arg![]() is one of the options listed in the
table below.
is one of the options listed in the
table below.
This commands sets the photoelectric cross-section used in XSPEC absorption models. (It does not set the cross-section for xswabs.)
| Name | Description |
|---|---|
| bcmc | default value; Balucinska-Church & McCammon (1992, ApJ 400, 699) with a new He cross-section based on (1998, ApJ 496, 1044) |
| obcm | bcmc with the old He cross-section |
| vern | Verner et al. (1996, ApJ 465, 487) |
Examples:
Run the XSPEC command xsect, setting abundances to OBCM:
sherpa> XSPEC XSECT OBCM
Reset the cross-section to the default value:
sherpa> XSPEC XSECT BCMC
cxchelp@head.cfa.harvard.edu